Schema-only Klonen einer Datenbank

Das Testen von Datenbanksystem ist ein sehr wichtiger Teil des Entwicklungsprozesses. Selbst wenn die Datenbank bereits in Betrieb genommen wurde, ist man noch nicht fertig mit Einstellungen und Verbesserungen. Deshalb soll es in diesem Artikel darum gehen, wie Sie eine Produktionsdatenbank für eben diese Zwecke erfolgreich klonen können.
Aktuelle Teststrategien
Beschäftigt man sich mit den aktuellen Strategien des Testens, wird ein Trend dazu sichtbar, dass Teile der Tests auf Produktionsebene durchgeführt werden. Das hat einige Vorteile. Das Anpassen an den Server und die Umgebung fällt um einiges leichter, da die Datenbank sich bereits in der Zielumgebung befindet. Außerdem kann mit “echten” Daten getestet werden. Egal wie gut erstellte Testdaten auch sind, es kann immer dazu kommen, dass an einen Spezialfall nicht gedacht wird. Somit sind Anpassungen, die abhängig vom Server oder den Daten sind, tatsächlich sinnvoll, auf der Produktionsebene zu testen. Ein Workflow, der sich dieses Konzept zu Nutze machte, ist das Erstellen einer CICD Pipeline. Zu diesem Thema haben wir bereits einen Artikel verfasst (Mainzer Datenfabrik GmbH ).
Aber bei all den Vorteilen, müssen auf jeden Fall die Risiken beachtet werden. Es wird mit Code gearbeitet, bei dem man noch nicht sicher weiß, ob er funktioniert. Das kann zu Wartezeiten für User führen, oder gar eine komplette Downtime des Servers bedeuten. Da es sich hier um die Produktionsdatenbank handelt, sollte das auf keinen Fall passieren. Ein anderer Punkt, der heutzutage sehr wichtig ist, ist der Datenschutz. Beim Testen könnte man Daten erhalten oder gar verändern, auf die man erst gar nicht Zugriff haben sollte. Aus diesem Grund ist es sehr wichtig zu unterscheiden, was getestet werden sollte und ob es wert ist, ein solches Risiko einzugehen.
Möglichkeiten
Wir wollen uns im Weiteren mit dem Fall beschäftigen, dass wir eine Produktionsdatenbank für Testzwecke klonen wollen. Dabei wollen wir nur die Schemas und Statistiken übertragen, ohne die Daten. Ein beispielhafter Anwendungsfall ist Performance Tuning von Queries. Dabei kann man zwischen zwei Möglichkeiten zum klonen wählen:
- “Generate Scripts” - Option
Mithilfe dieser Option wird ein Skript generiert, welches die gewünschte Datenbank klonen kann. Hierbei gibt es sehr viele Einstellungsmöglichkeiten. Wenn man nicht genau weiß, was man braucht, kann es schnell kompliziert werden. Zudem ist ratsam, die Generierung des Skriptes zu einer Zeit zu machen, in der die Datenbank wenig gebraucht wird. - “DBCC CLONEDATABASE” - Befehl
Dieser Befehl wurde im Laufe von MS SQL Server 2014 eingeführt. Er stellt eine leichtere und schnellere Alternative zu dem Skript dar. Hier wird eine geklonte Datenbank auf derselben Serverinstanz erstellt. Dieser Klon dient dabei ausschließlich zu Testzwecken.
Möchte man eine Datenbank, anders als in unserem Beispiel, mit Daten klonen, gibt es auch hierfür Möglichkeiten.
- "Generate Scripts”- Option, aber in den Einstellungen wählt man auch Daten aus (mehr dazu später)
- Backup und Restore, besonders mit einem “Copy-only” Backup (kein Eingriff auf Logs und LSN)
- Copy Database Wizard von SSMS
- Export/Import Wizard von SSMS
Klonen mit “Generate Scripts”
Als erstes wollen wir die Skript Methode zeigen. Zur Veranschaulichung haben wir zwei Server aufgesetzt (DemoServer1 und DemoServer2) und eine Version der AdventureWorks Datenbank auf einem Server hinzugefügt.
Das Ziel ist es nun, die Datenbank von Server1 auf Server2 mithilfe des Skriptes zu klonen. Der erste Schritt hierbei ist, das Tool zum Generieren des Skriptes zu öffnen. Dieses findet man in den Tasks, wenn man die Optionen mit Rechtsklick auf die Datenbank öffnet.
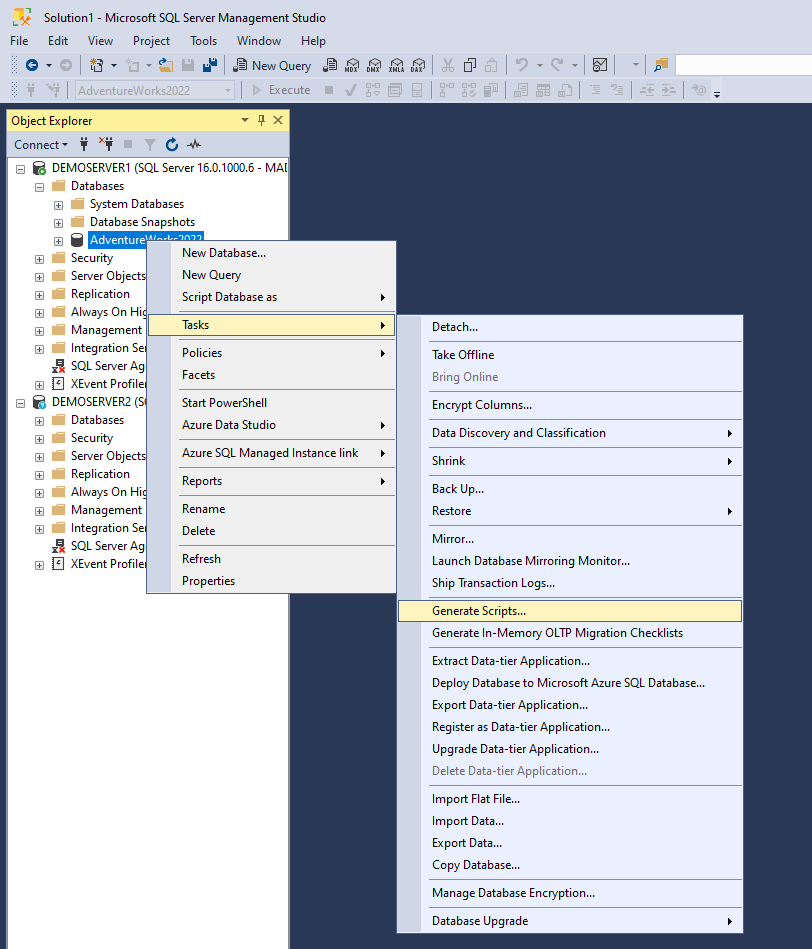
Daraufhin öffnet sich ein Dialogfeld. Hier klickt man sich durch, bis man zu den Optionen kommt. In unserem Beispiel haben wir das Skript auf der Festplatte gespeichert.
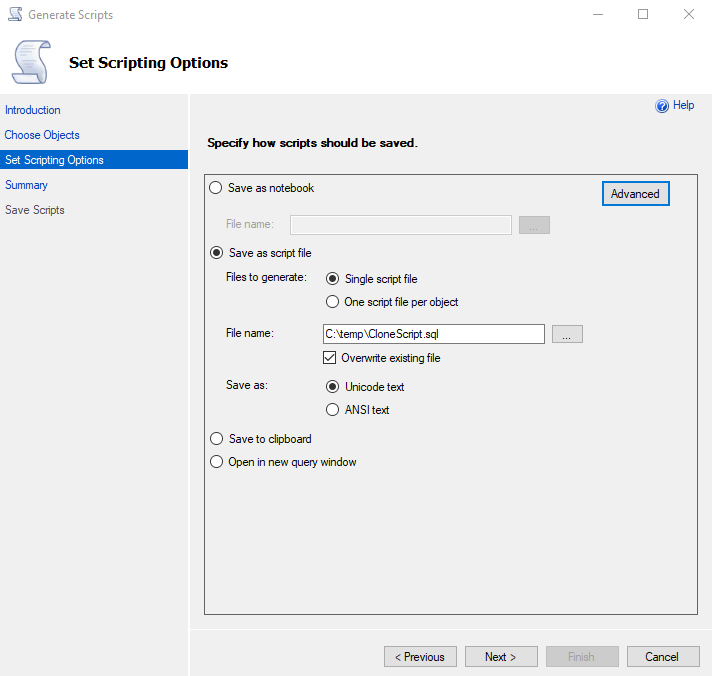
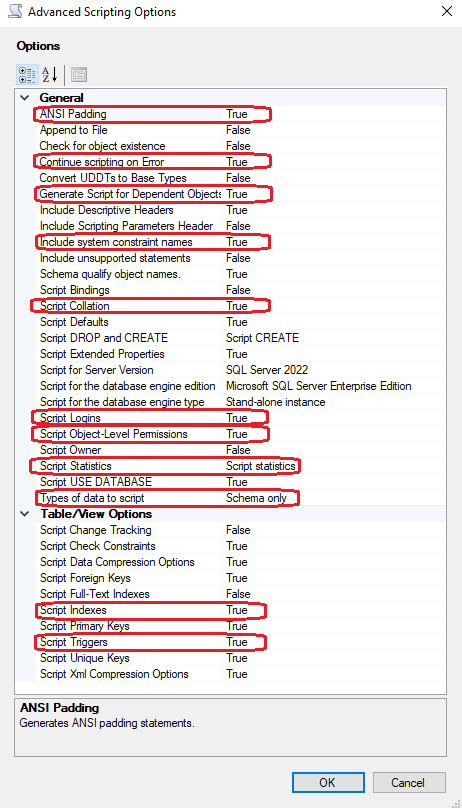
Zu den wichtigsten Einstellungen kommt man, indem man auf den Advanced Button drückt. Hier öffnet sich eine Liste mit Feineinstellungen für das Skript. Die Einstellungen, die für unseren Zweck wichtig sind, haben wir im nächsten Bild markiert.
Wie oben schon erwähnt, kann man auch mit diesem Tool die Daten einer Datenbank klonen. An dieser Stelle muss in der Option “Types of Data to Script” nur die Einstellung “Schema and Data” ausgewählt werden.
Fährt man nun fort, wird das Skript fertig gestellt. Dieses muss nur noch auf dem zweiten Server ausgeführt werden und man hat eine geklonte Datenbank. Zum Ausführen kann man entweder ebenfalls SSMS oder SQLCMD benutzen. Aber wie bereits in der Übersicht erwähnt, sollte das Skript zu einer Zeit erstellt werden, in der die Datenbank nicht stark beansprucht wird. Ansonsten könnte es zu längeren Wartezeiten für andere User kommen.
Klonen mit DBCC CLONEDATABASE
Als Alternative wurde im Laufe von SQL Server 2014 der Befehl DBCC CLONEDATABASE eingeführt. Die Idee dahinter ist fast schon simpel. Es wird eine neue Datenbank erstellt, die sich die Objekte aus der zu klonenden Datenbank kopiert und für sich selbst neu erstellt. Am Ende erhält man eine Read-Only Kopie der Datenbank. Es ist anzumerken, dass sich diese Kopie ausschließlich zu Testzwecken benutzen lässt und es nicht ratsam ist, diese als Produktionsdatenbank zu verwenden.
Schaut man sich nun die tatsächliche Anwendung des Befehls an, ist das einfacher im Vergleich zur ersten Methode von oben. Man muss nur folgenden Code ausführen.
DBCC CLONEDATABASE ('DatabaseName','NewDatabaseName')
Damit auch Änderungen an der Datenbank gemacht werden können, kann man danach den Status auf Read-Write ändern. Das geht ganz einfach mithilfe dieses Befehls.
USE master ALTER DATABASE DatabaseName SET READ_WRITE WITH NO_WAIT GO
Will man darüber hinaus ebenfalls die Last des Produktionsservers vermindern, ist es ratsam den Klon in eine Testumgebung zu schieben. Das kann man zum Beispiel über ein Detach und Attach der Datenbank erreichen.
Problem mit DBCC CLONEDATABASE
Während unserer Recherche und unserem Testen ist bei uns ein Fehler aufgetreten, über den wir ein wenig sprechen wollen. In einem Spezialfall kann der Versuch des Klonens fehlschlagen. Die Nachricht dazu sieht wie folgt aus:
Cannot insert duplicate key row in object 'sys.sysschobjs' with unique index 'clst'. The duplicate key value is ('Value').
Der Fehler trat nur dann auf, wenn eine Datenbank auf einer neueren SQL Version läuft, als die, auf der sie erstellt wurde. Der Grund dafür ist die ‘model’ Datenbank. Diese enthält die Vorlage für System Tabellen, die jede Datenbank hat. Immer, wenn eine Datenbank neu erstellt wird, werden anhand von ‘model’ die System Tabellen erzeugt. Dabei ist vorgegeben, welchen Namen und welche ID die Objekte haben. Diese IDs sind immer gleich. So können die Inhalte von demselben Objekt ganz einfach in das neue übertragen werden. Aber wieso kommt es dann zu einem doppelten ID Value?
Das Problem ist, jede Version von SQL Server hat auch eine eigene Version von ‘model’. Mit jeder Version kommen weitere System Tabellen hinzu. Zum Beispiel hat die 2016 Version noch nicht die Tabelle “db_ledger_blocks”. Diese kam erst mit der Version von 2022 hinzu. Da das alte System nichts von der Tabelle weiß, kann es passieren, dass ein User erstelltes Objekt diese ID zugewiesen bekommt. Bei diesem Objekt kann es sich dabei um einfache Tabellen der Datenbank, Trigger oder Funktionen handeln. Wird die Datenbank auf eine neue Version geupdated, werden die fehlenden Tabellen aus ‘model’ nachträglich erstellt. Die IDs unterscheiden sich aber auch hier. Unabhängig ob die vorgesehene ID für eine Tabelle frei ist oder nicht, wird eine neue ID zugewiesen. Somit wissen wir nun, warum es Probleme mit den ID Values gibt.
Was kann man mit dem Wissen nun anfangen? Es bräuchte einen Weg, wie man entweder die User erstellten Objekte oder die Tabellen in ‘model’ ändern könnte. Aber das ist aus mehreren Gründen keine gute Idee. Zum einen befinden wir uns immer noch auf Produktionsebene. Das heißt, die erstellten Objekte haben einen gewissen Nutzen. Deswegen sollte man auf keinen Fall anfangen, daran irgendwas zu ändern oder gar zu löschen. Des Weiteren ist es immer eine schlechte Idee an der ‘model’ Datenbank herum zu schrauben. Denn sie dient immer noch als template für alle Datenbanken, die man später erstellen möchte. Hinzu kommt, dass Microsoft jeglichen Eingriff auf diese Tabellen verhindert. Die möglichen Mittel, die übrig bleiben, sind somit sehr begrenzt. Aber damit die Inkonsequenz perfekt ist, scheint die Funktion in einem späteren Schritt zu erkennen, dass die Objekte, die blockiert sind, an einer anderen Stelle zu finden sind. In einem Test haben wir die blockierenden Objekte gelöscht und später herausgefunden, dass es nach dem Klonen kein Objekt mit der blockierten ID gibt.
Wie kann man nun diesen Fehler beheben? Wie schon gesagt, hat man einmal den Fehler, bleiben nicht mehr viele Möglichkeiten übrig. Tatsächlich wurde der Fehler in den Versionen 2014 und 2016 gelöst. Hier kann auch ein Klon erstellt werden, trotz dieser kollidierenden IDs. Für die Versionen danach gibt es unseres Wissens nach momentan keine Lösung. Aber wie oben bereits angesprochen, tritt der Fehler ausschließlich dann auf, wenn eine ältere Datenbank auf eine neue Version überführt wurde. Ist das nicht der Fall, kann mit DBCC CLONEDATABASE trotzdem schnell und einfach eine schema-only Kopie einer Datenbank erstellt werden.
Unsere Expert:innen stehen Ihnen bei allen Fragen rund um Ihre IT Infrastruktur zur Seite.
Kontaktieren Sie uns gerne über das
Kontaktformular und vereinbaren ein unverbindliches
Beratungsgespräch mit unseren Berater:innen zur
Bedarfsevaluierung. Gemeinsam optimieren wir Ihre
Umgebung und steigern Ihre Performance!
Wir freuen uns auf Ihre Kontaktaufnahme!
55118 Mainz
info@madafa.de
+49 6131 3331612
Freitags:

