Python in SQL Server (Lesson 3 & 4)
Python ist eine interpretierte, interaktive und objektorientierte Programmiersprache. Sie enthält Module, Ausnahmen, dynamische Typisierung und dynamische Datentypen auf sehr hohem Niveau und Klassen. Python verfügt über Pakete, die verschiedene Kategorien von Funktionen in Bibliotheken (auch Pakete genannt) kapseln. Für die Anwendung der statistischen Analyse benötigt man oft Beispieldaten. Angenommen wir haben bereits Beispieldatensätze zur Hand, so können wir Python zur Analyse der statistischen Berechnungen und Algorithmen verwenden. Um diese Berechnungen durchführen zu können, sollte man die üblichen Programmierkonstrukte wie Variablen, Datentypen, Operatoren und Schleifen usw. kennen.
Lektion 3
Die meisten der in Python verfügbaren Programmierkonstrukte sind auch in T-SQL verfügbar. Es ist allerdings nicht unsere Absicht, Python in all seinen Einzelheiten zu lernen, sondern explizit Python-Konstrukte kennenzulernen, die es uns ermöglichen, die einzigartigen Python-Bibliotheken und Datenverarbeitungs-/ Berechnungsmechanismen zu nutzen, die in T-SQL nicht verfügbar sind. In dieser Lektion lernen wir die grundlegenden Konzepte von Python kennen, die gerade ausreichen, um Python-Funktionen und -Pakete anzuwenden, damit wir die Konzepte für die vom SQL Server Data Repository übergebenen Daten anwenden können.
Python – Version, Pakete und Datensätze
Wir haben bereits in der letzten Lektion gelernt, wie man die Version der Python-Laufzeitumgebung überprüft, mit der die Datenbank-Engine kommuniziert. Es ist wichtig, die Pythonversion zu kennen, mit der Sie arbeiten, da Sie so herausfinden können, was von einer bestimmten Version von Python unterstützt wird. Mit sp_execute_external_script und einer einfachen Python-Eigenschaft sys.version können Sie die Details der Python-Version wie unten gezeigt überprüfen. Die Print-Funktion gibt die Ausgabe auf der Nachrichtenkonsole von SQL Server Management Studio (SSMS) aus. Unser Fokus liegt nun auf der Entwicklung der Grundlagen von Python, wobei wir die Details von sp_execute_external_script, in der weiter unten folgenden Lektion 4 besprechen.
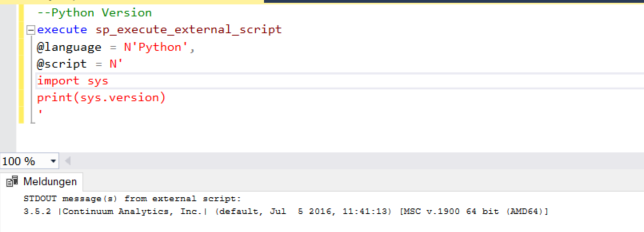
Der nächste Schritt ist die Erkundung der verschiedenen Bibliotheken, die bei der Python Installation standardmäßig zur Verfügung gestellt werden. Zusätzlich können Sie hier eine Übersicht über die verschiedenen Bibliotheken finden. Mithilfe der Importfunktion können Sie jede beliebige Bibliothek laden. Im obigen Code haben wir uns bereits ein Beispiel für die Verwendung dieser Funktion angesehen.
Variablen und Kommentare
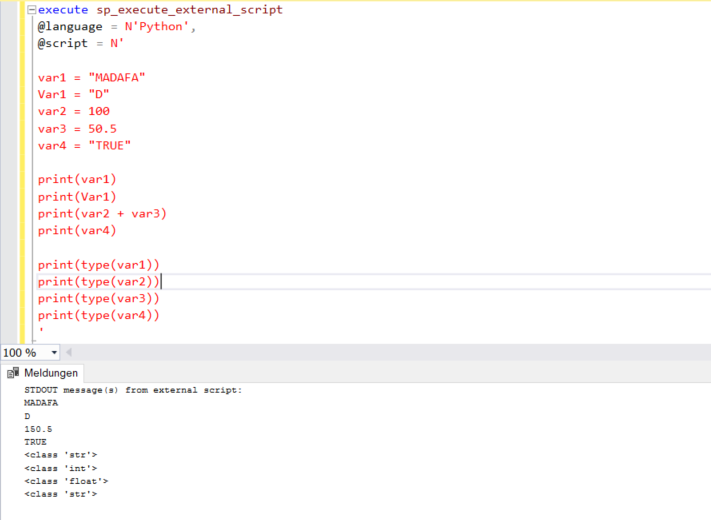
In Python wird eine Variable mithilfe des Zuweisungsoperators “=“ erstellt. Python Variablen benötigen keine explizite Deklaration. Der Datentyp der Variablen wird durch die in R gespeicherten Daten bestimmt. Der Code kann in Python mit dem #-Zeichen kommentiert werden. Der Operand links vom “=”-Operator ist der Name der Variablen und der Operand rechts vom “=”-Operator ist der in der Variablen gespeicherte Wert. Lassen Sie uns diese Konzepte anhand eines Beispiels verstehen.
execute sp_execute_external_script
@language = N'Python',
@script = N'
var1 = "MADAFA"
Var1 = "D"
var2 = 100
var3 = 50.5
var4 = "TRUE"
print(var1)
print(Var1)
print(var2 + var3)
print(var4)
print(type(var1))
print(type(var2))
print(type(var3))
print(type(var4))
'Beim Ausführen des oben stehenden Codes sollte die Ausgabe wie unten dargestellt aussehen. Nachfolgend sind die Punkte aufgeführt, die Sie aus dem obigen Beispiel ableiten können:
- Variablen können mit dem Operator **“=“ (Zuweisung) erstellt werden.
- Bei Variablen muss die Groß-/Kleinschreibung beachtet werden. “Var1” und “var1” werden als unterschiedliche Variablen betrachtet.
- Der Datentyp der Variablen wird durch den Typ der in der Variablen gespeicherten Daten bestimmt.
- Sie können den Wert von Variablen mit der Print-Funktion abrufen.
- Die Type-Funktion kann für Variablen verwendet werden, um den Datentyp der Variablen zu bestimmen, der in fünf Haupttypen unterteilt ist – Integer, String, Liste, Tupel und Dictionary.
- Es gibt auch andere Datenstrukturtypen, aber wir beschränken uns hier auf die Grundtypen.
Arithmetik, Operatoren, Schleifen
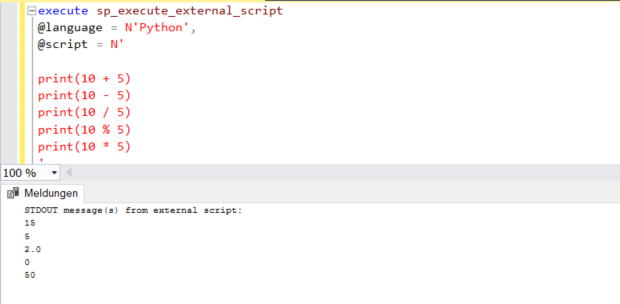
Die folgende Tabelle zeigt eine Liste der arithmetischen und logischen Operatoren in Python. Es ist keine vollständige Liste, jedoch deckt sie wichtige Operatoren ab, die Sie verwenden können, wenn Sie mit dem Erlernen von Python beginnen.
| Operator | Beschreibung |
|---|---|
| + | Addition |
| – | Subtraktion |
| * | Multiplikation |
| / | Division |
| ** | Potenz |
| % | Rest (modulo) |
| < | Kleiner |
| <= | Kleiner gleich |
| > | Größer |
| >= | Größer gleich |
| == | Gleich |
| != | Ungleich |
| | | Oder |
| & | Und |
Obwohl diese Operatoren selbsterklärend sind, finden Sie im Folgenden ein grundlegendes Beispiel dafür, wie Sie diese Operatoren verwenden können. Wir haben diese Operatoren für tatsächliche Werte verwendet. Sie können diese Operatoren auf die gleiche Weise aber auch auf Variablen anwenden.
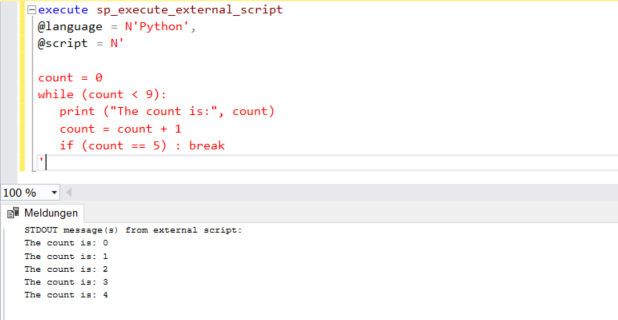
Wenn wir unsere Daten zur Hand haben, ist die Wahrscheinlichkeit groß, dass wir Schleifen in die Daten einfügen müssen, um einige statistische Berechnungen durchzuführen. Daher müssen wir mindestens eine Schleifen-Technik in Python kennenlernen. Im Folgenden finden Sie ein einfaches Beispiel für eine While-Schleife.
execute sp_execute_external_script
@language = N'Python',
@script = N'
count = 0
while (count < 9):
print ("The count is:", count)
count = count + 1
if (count == 5) : break
'In diesem Beispiel weisen wir einer Variablen count den Wert 0 zu. Wir geben den Wert von “count” in der Schleife aus und erhöhen den Wert von i. Außerdem legen wir eine Bedingung fest, die besagt, dass wir die Schleife mit der Anweisung break verlassen, wenn der Wert von “count” 5 erreicht.
Bis jetzt haben wir uns nur Vorgänge angeschaut, die wir auch mit T-SQL erreichen können. Aber sobald die Daten aus den SQL Server-Datentabellen/-Ansichten an die Python-Laufzeitumgebung zur Verarbeitung der Daten übergeben werden, müssen wir Programmierkonstrukte in der Sprache Python verwenden. Da wir nun wissen, wie man in Python arithmetische Berechnungen auf Daten anwendet, werden wir in der nächsten Lektion lernen, wie man Daten zwischen T-SQL und Python akzeptiert und empfängt.
Lektion 4
Ein Großteil der Datenverarbeitungsaufgaben wird im Allgemeinen bevorzugt in T-SQL erledigt. Wie wir in der ersten Lektion erklärt haben, wäre es sinnvoll, Python für spezielle Aufgaben wie statistische Berechnungen, maschinelles Lernen, Verarbeitung natürlicher Sprache usw. zu nutzen. Betrachten wir einen Anwendungsfall, in dem wir Statistiken über quantitative Daten aus einer Tabelle berechnen müssen, die in einer Beispieldatenbank gespeichert sind und auf einer Instanz von SQL Server 2017 gehostet werden. Die vorbereitende Datenanalyse und -exploration für maschinelles Lernen beginnt in der Regel mit deskriptiven Statistiken. Für die gleiche Berechnung von grundlegenden numerischen Parametern wie Mittelwert, Median, Quartile, usw. werden Diagramme wie Histogramme, Scatterplots und Boxplots usw. Seite an Seite mit diesen Statistiken analysiert.
Wir wollen nun lernen, wie man diese Statistiken mit T-SQL und R für quantitative und umfangreiche Daten, die in einer SQL Server-Tabelle gespeichert sind, ableiten kann.
SP_EXECUTE_EXTERNAL_SCRIPT
Wir haben dieses Verfahren bereits in den vorangegangenen Lektionen gesehen. Nachfolgend finden Sie eine Erläuterung der Syntax und einige Punkte, die bei der Verwendung dieses Befehls zu beachten sind:
- Die Ausführung externer Skripte muss auf der Instanz von SQL Server aktiviert sein, wie in der vorherigen Lektion beschrieben.
- Für den Parameter @language sollte die Sprache R angegeben sein, um R-Skripte auszuführen.
- Sie können die Abfrage und den Namen der Eingabedatensätze mit dem entsprechenden Eingabeparameter (@input_data_1 und @input_data_1_name) angeben. Wenn Sie keinen Namen für den Eingabedatensatz angeben, wird der Standardname verwendet, z.B. “InputDataSet”.
- Sie können auch einen Namen für den Ausgabedatensatz angeben, ansonsten würde der Standardname “OutputDataSet” verwendet werden.
- Um die Ausgabedaten in der Ergebnismenge abzurufen, müssen Sie das Schlüsselwort WITH RESULT SETS und die Definition der Ausgabedaten angeben.
sp_execute_external_script
@language = N'language',
@script = N'script'
[ , @input_data_1 = N'input_data_1']
[ , @input_data_1_name = N'input_data_1_name']
[ , @output_data_1_name =N'output_data_1_name']
[ , @parallel = 0 | 1 ]
[ , @params =N'@parameter_name data_type
[ OUT | OUTPUT ] [ ,...n ]' ]
[ , @parameter1 = 'value1' [ OUT | OUTPUT ]
[ ,...n ] ]
[ WITH <execute_option> ]
[;]
<execute_option> ::=
{
{ RESULT SETS UNDEFINED }
| { RESULT SETS NONE }
| { RESULT SETS ( <result_sets_definition> ) }
}
<result_sets_definition> ::=
{
(
{ column_name
data_type
[ COLLATE collation_name ]
[ NULL | NOT NULL ] }
[,...n ]
)
| AS OBJECT
[db_name . [schema_name] . | schema_name .]
{table_name | view_name | table_valued_function_name }
| AS TYPE [ schema_name.]table_type_name
}Datenaustausch zwischen Python und T-SQL
Lassen Sie uns versuchen, die oben genannten Punkte anhand eines Beispiels zu verstehen. Nehmen wir an, wir haben die AdventureWorks Data Warehouse Beispieldatenbank. Faktentabellen enthalten im Allgemeinen quantitative Daten und Dimensionstabellen enthalten qualitative Daten. Daher eignen sich Faktentabellen natürlich gut für statistische Analysen. Die relevantesten numerischen Daten würden sich auf die Verkäufe in der AdventureWorks-DW-Datenbank beziehen:
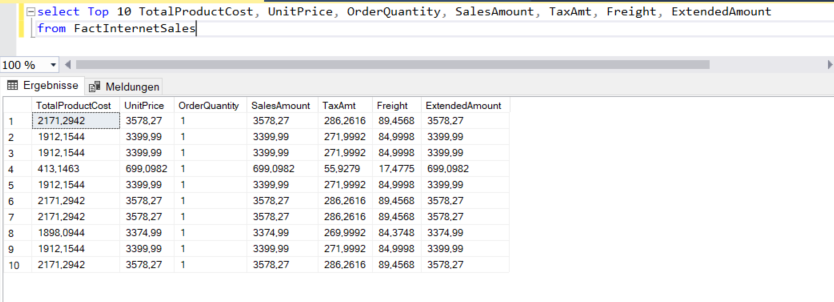
Stellen Sie sich einen Anwendungsfall vor, in dem wir mit einem Minimum an Code und Komplexität grundlegende deskriptive Statistiken für Felder mit numerischen Werten berechnen wollen. Dazu würden wir unsere Daten für Berechnungen an Python übergeben und die berechnete Ausgabe aus Python in T-SQL abrufen. Die Tabelle FactInternetSales enthält mehr als 60k Datensätze, die sich auf die Verkaufsdaten beziehen. Mit einer einzigen Codezeile in Python können wir alle diese Statistiken berechnen – was folgendes Beispiel aufzeigt. Lassen Sie uns verstehen, wie dieses Beispiel aufgebaut ist und wie Daten zwischen Python und T-SQL ausgetauscht werden:
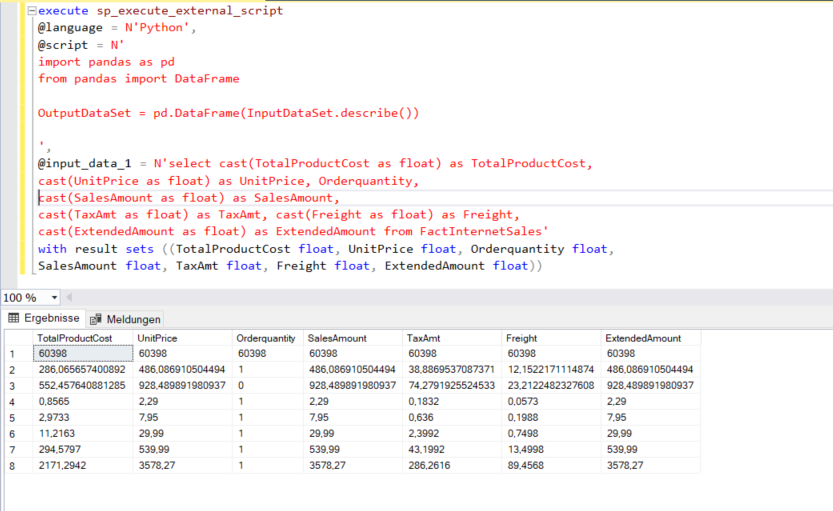
- Zunächst verwenden wir den Befehl sp_execute_external_script mit dem Parameter @language, bei dem wir Python angeben.
- Mit dem Parameter @script geben wir das Python-Skript an.
- In @input_data_1 wurde die T-SQL-Abfrage angegeben, die die relevanten Felder aus der Tabelle FactInternetSales abruft. Die Felder mit dem Datentyp “Geld” werden in Float konvertiert, da “Geld” kein von Python unterstützter Datentyp ist.
- Im letzten Teil der Abfrage hat das Schlüsselwort with result sets angegeben, dass eine Ausgabeergebnismenge erwartet wird und das Schema der Ausgabedatenmenge wurde angegeben.
- In der Beschreibung der Verwendung des Befehls sp_execute_external_script wird erwähnt, dass der Eingabe- und Ausgabedatensatz in Python die Form eines DataFrames haben muss. Ein DataFrame ist eine Datenstruktur in Python, die gleichbedeutend mit einer Tabelle in SQL Server ist. InputDataSet wird standardmäßig in Form eines DataFrames an Python gesendet. OutputDataSet muss eventuell in einen DataFrame konvertiert werden. Die DataFrame-Struktur ist in einer Bibliothek namens Pandas enthalten. Daher haben wir diese Bibliothek zu Beginn des Skripts mit dem Schlüsselwort import importiert.
- Die DataFrame-Struktur enthält eine eingebaute Funktion namens describe zur Berechnung grundlegender Statistiken für einen Datensatz. Wir übergeben die Eingabedaten an diese Funktion, konvertieren die Ausgabe mit der Funktion DataFrame in einen DataFrame und weisen das Ergebnis dem Ausgabestrom zu, wobei wir den Standard-Ausgabenamen, d.h. OutputDataSet, verwenden.
Die Endausgabe ist die Berechnung von Anzahl, Mittelwert, Standardabweichung, Minimum, Maximum und Quartilen wie 25%, 50% und 75%. Die Formeln und die Bedeutung dieser Statistiken würden den Rahmen dieses Tutorials sprengen. Es handelt sich jedoch um grundlegende Berechnungen, die Ihnen bereits bekannt sein dürften, wenn Sie sich mit Datenanalyse und Datenwissenschaft beschäftigen. Wenn Sie sich mit diesen Formeln nicht auskennen, bietet es sich an dieser Stelle an, sich auf dieses Tutorial aufbauend damit zu beschäftigen. Zusammenfassend zeigen wir Ihnen im Folgenden unsere Ausgabe:
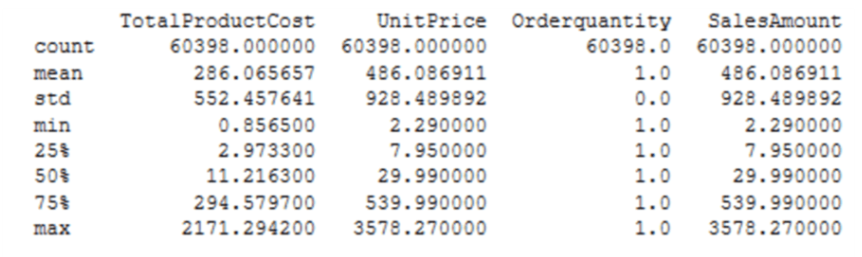
Als Nächstes sehen Sie, wie Sie all diese Statistiken mit einer einzigen Codezeile in Python berechnen können. Überlegen Sie sich, wie Sie die gleiche Ausgabe in T-SQL erreichen können. Dann können Sie die Komplexität der Implementierung in T-SQL gegenüber Python beurteilen.
execute sp_execute_external_script
@language = N'Python',
@script = N'
import pandas as pd
from pandas import DataFrame
OutputDataSet = pd.DataFrame(InputDataSet.describe())
',
@input_data_1 = N'select cast(TotalProductCost as float) as TotalProductCost,
cast(UnitPrice as float) as UnitPrice, Orderquantity,
cast(SalesAmount as float) as SalesAmount,
cast(TaxAmt as float) as TaxAmt, cast(Freight as float) as Freight,
cast(ExtendedAmount as float) as ExtendedAmount from FactInternetSales'
with result sets ((TotalProductCost float, UnitPrice float, Orderquantity float,
SalesAmount float, TaxAmt float, Freight float, ExtendedAmount float))Nachdem wir nun verstanden haben, wie die statistische Leistungsfähigkeit von Python auf Datensätze angewendet werden kann, die mit T-SQL aus SQL Server-Datenrepositories abgerufen wurden, besteht der nächste logische Schritt darin, mithilfe von Visualisierungen einige Erkenntnissen über Daten zu gewinnen. Wie Sie hier vorgehen können, erklären wir in der nächsten Lektion.
Unsere Expert:innen stehen Ihnen bei allen Fragen rund um Ihre IT Infrastruktur zur Seite.
Kontaktieren Sie uns gerne über das
Kontaktformular und vereinbaren ein unverbindliches
Beratungsgespräch mit unseren Berater:innen zur
Bedarfsevaluierung. Gemeinsam optimieren wir Ihre
Umgebung und steigern Ihre Performance!
Wir freuen uns auf Ihre Kontaktaufnahme!
55118 Mainz
info@madafa.de
+49 6131 3331612
Freitags:

