Grafische Analyse mit Python (Lesson 5)
In der letzten Lektion unseres Tutorials analysieren wir einen Beispieldatensatz mit Python. Für visuelle Analysen in SQL Server verwenden Entwickler in erster Linie Excel/ SSRS/ Power BI/ Powerpivot/ Powerview oder andere ähnliche Tools, um Daten aus Tabellen/ Sichten zu beziehen und Visualisierungen zu erstellen. Manchmal benötigen vor allem Datenanalysten/ Datenwissenschaftler statistische Visualisierungen für eine tiefergehende Datenanalyse. Außerdem ist es bei großen Datenmengen aus verschiedenen Gründen nicht immer möglich, die gesamten Daten von externen Tools lesen zu lassen.
Lektion 5
Im Allgemeinen ist die Erstellung statistischer Visualisierungen sehr viel code-intensiver als die Erstellung derselben mit “R”. Python bietet mit matplotlib eine integrierte Bibliothek für grafische Analysen, sowie integrierte Funktionen zur Erstellung grafischer Diagramme für eine schnelle Datenanalyse, die bei der Entwicklung/Erforschung von Data-Science-Algorithmen sehr nützlich sein können. In dieser Lektion werden wir uns eine der Möglichkeiten zur grafischen Analyse von Daten mit Python ansehen, um die Datenverteilung und die Ausreißeranalyse zu verstehen.
Verwendung von Matplotlib
In Python werden Bilder in der Regel mithilfe eines Matplotlib-Plots für die grafische Ausgabe erstellt. Sie können die Ausgabe dieses Plots erfassen und das Bild in einem varbinary-Datentyp speichern, um es in einer Anwendung wiederzugeben oder Sie können die Bilder in einem der unterstützten Dateiformate (.JPG, .PDF, usw.) speichern. In Python können wir die Ausgabe von Plotting-Funktionen sammeln und in einer Datei speichern. Im Folgenden erklären wir Ihnen anhand eines Beispiels wie Sie dabei vorgehen.
Diagramme und Plots erstellen
In unserem Beispiel verwenden wir die AdventureWorks Data Warehouse Datenbank. Bei dieser Datenbank handelt es sich um ein Data Warehouse, das Dimensionen und Faktentabellen enthält. Für uns interessant ist die Tabelle FactResellerSales mit etwa 60.000 Datensätzen. Nehmen wir an, dass wir Transaktionen analysieren wollen, bei denen das Produkt mit Verlust verkauft werden musste. Wir können dies auch mit einer einfachen T-SQL-Abfrage herausfinden, aber unsere Absicht ist es, Transaktionen mit außergewöhnlich hohem Verlust zu finden. In diesem Fall kann es allerdings viele Produkte geben, die im Vergleich zu allen anderen Transaktionen mit Verlust verkauft wurden.
Um den Verlust zu analysieren, müssen wir im Wesentlichen zwei Parameter kennen – die Produktionskosten und den Verkaufsbetrag. Bei diesen Daten handelt es sich um Transaktionsdaten. Die meisten Entwickler arbeiten bei ihrer täglichen Arbeit mit mindestens einer transaktionalen Datenbank, so dass dieses Beispiel vergleichbar sein sollte. Es kann Produkte geben, die in einem Jahr viele Male zum gleichen Preis verkauft wurden. Wir müssen also jede Transaktion für ein Produkt mit eindeutigen Produktionskosten, Verkaufsbetrag und Geschäftsjahr finden. Sie können die folgende Abfrage verwenden um die Ergebnismenge von 60.000 Zeilen auf 5347 Zeilen zu reduzieren.
select distinct F.ProductKey, F.TotalProductCost, F.ExtendedAmount, F.OrderQuantity,
F.SalesAmount, Year(F.OrderDate) as OrderYear,
P.EnglishProductName, C.EnglishProductCategoryName, S.EnglishProductSubcategoryName
from FactResellerSales F
join DimProduct P on F.ProductKey = P.ProductKey
join DimProductSubcategory S on S.ProductSubcategoryKey = P.ProductSubcategoryKey
join DimProductCategory C on C.ProductCategoryKey = S.ProductCategoryKey
Order by F.ProductKey, Year(F.OrderDate)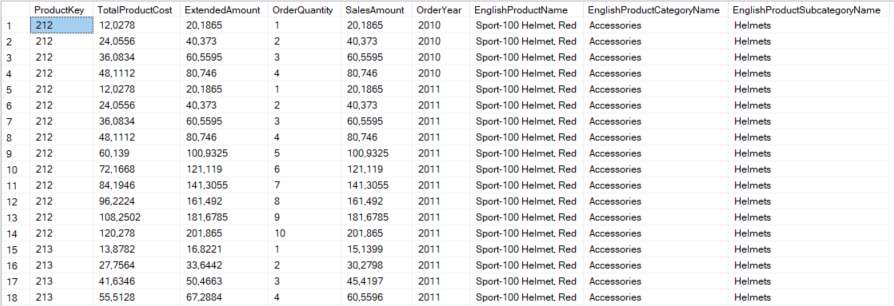
Wir haben qualitative Attribute des Produkts wie Produktkategorie und Produktunterkategorie aufgenommen, indem wir die entsprechenden Tabellen verbunden haben. Da wir diesen Datensatz mehrfach verwenden müssen, ist es ratsam, eine Ansicht mit der obigen Abfrage zu erstellen. Wir haben eine Ansicht mit dem Namen MyPythonTestData unter Verwendung der obigen Definition erstellt. Nun ist es an der Zeit, unser erstes Diagramm zu erstellen. Führen Sie hierzu den folgenden Code aus.
execute sp_execute_external_script
@language = N'Python',
@script = N'
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
# Create data
colors = (0,0,0)
area = np.pi*3
fig_handle = plt.figure(figsize=(10,10))
plt.scatter(InputDataSet.ExtendedAmount, InputDataSet.TotalProductCost, s=area, c=colors, alpha=0.5)
plt.title("Scatter plot of Bikes Data")
plt.xlabel("Sales Amount")
plt.ylabel("Total Production Cost")
plt.savefig("C:\Test\subcategory-scatterplot.png")
',
@input_data_1 = N'Select cast(TotalProductCost as float) TotalProductCost, cast(ExtendedAmount as float) ExtendedAmount from MyPythonTestData where EnglishProductCategoryName = ''Bikes'''Hier erstellen wir ein Matplotlib-Diagramm mit der figure-Funktion im Python-Skript. In den folgenden Codezeilen geben wir die Größen der Ausgabedatei sowie den Dateipfad an. Mit der Scatter-Funktion erstellen wir ein Streudiagramm, in dem wir ExtendedAmount auf der x-Achse und TotalProductCost auf der y-Achse auftragen. Sobald die Ausgabe des Diagramms erstellt ist, speichern wir die Ausgabe mit der Funktion savefig in einer Datei. Die Ausgabe des Diagramms sollte wie unten dargestellt aussehen.
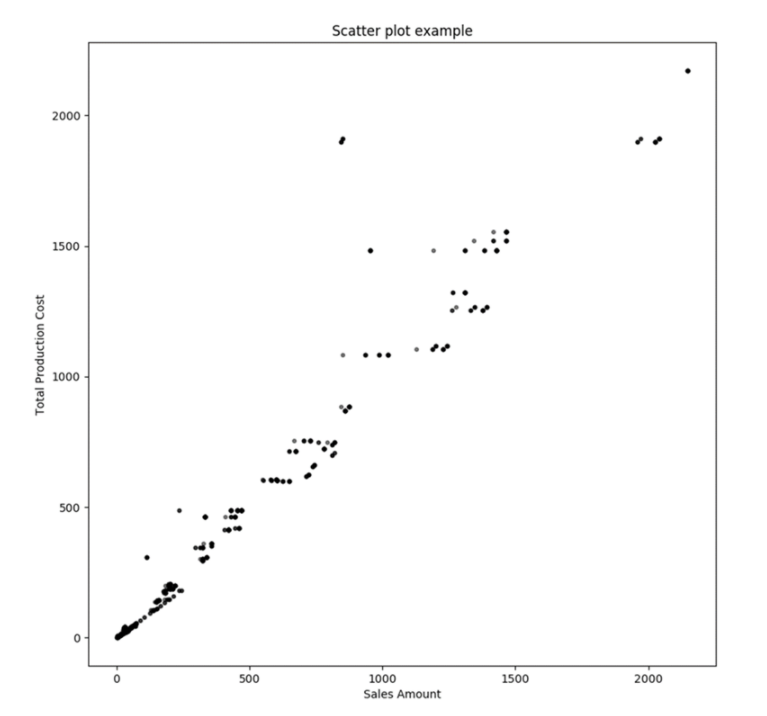
Um die Daten detailliert zu analysieren, müssen wir die Datenpunkte nach Kategorien einfärben. Auf diese Weise lassen sich die Ausreißer zusammen mit ihrer Kategorie sofort erkennen. Um dies in Python zu erreichen ist folgender Code erforderlich. Bibliotheken wie Bokeh, GGPlot2, Plotly können für einfachere und bessere Visualisierungen in Python verwendet werden. Für einige dieser Bibliotheken ist eine kostenpflichtige Lizenz erforderlich, und der Export der Ausgabe aus diesen Bibliotheken in eine Bilddatei mit T-SQL ist ebenfalls nicht allgemein bekannt oder getestet. Um den untenstehenden Code besser zu verstehen, können Sie die matplotlib-Dokumentation hier im Detail nachlesen.
execute sp_execute_external_script
@language = N'Python',
@script = N'
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
# Create data
colors = (0,0,0)
area = np.pi*10
fig_handle = plt.figure(figsize=(10,10))
fig, ax = plt.subplots(figsize=(10,10))
df1 = InputDataSet[InputDataSet["EnglishProductCategoryName"] == "Accessories"]
df2 = InputDataSet[InputDataSet["EnglishProductCategoryName"] == "Bikes"]
df3 = InputDataSet[InputDataSet["EnglishProductCategoryName"] == "Components"]
df4 = InputDataSet[InputDataSet["EnglishProductCategoryName"] == "Clothing"]
ax.scatter(df1.ExtendedAmount, df1.TotalProductCost, c="black", label="Accessories",alpha=0.3, s=area, edgecolors="none")
ax.scatter(df2.ExtendedAmount, df2.TotalProductCost, c="red", label="Bikes",alpha=0.3, s=area, edgecolors="none")
ax.scatter(df3.ExtendedAmount, df3.TotalProductCost, c="green", label="Components",alpha=0.3, s=area, edgecolors="none")
ax.scatter(df4.ExtendedAmount, df4.TotalProductCost, c="blue", label="Clothing",alpha=0.3, s=area, edgecolors="none")
ax.legend()
plt.title("Scatter plot of Bikes Data")
plt.xlabel("Sales Amount")
plt.ylabel("Total Production Cost")
plt.savefig("c:\Test\colored-scatterplot.png")
',
@input_data_1 = N'Select cast(TotalProductCost as float) TotalProductCost, cast(ExtendedAmount as float) ExtendedAmount, EnglishProductCategoryName, EnglishProductSubCategoryName from MyPythonTestData'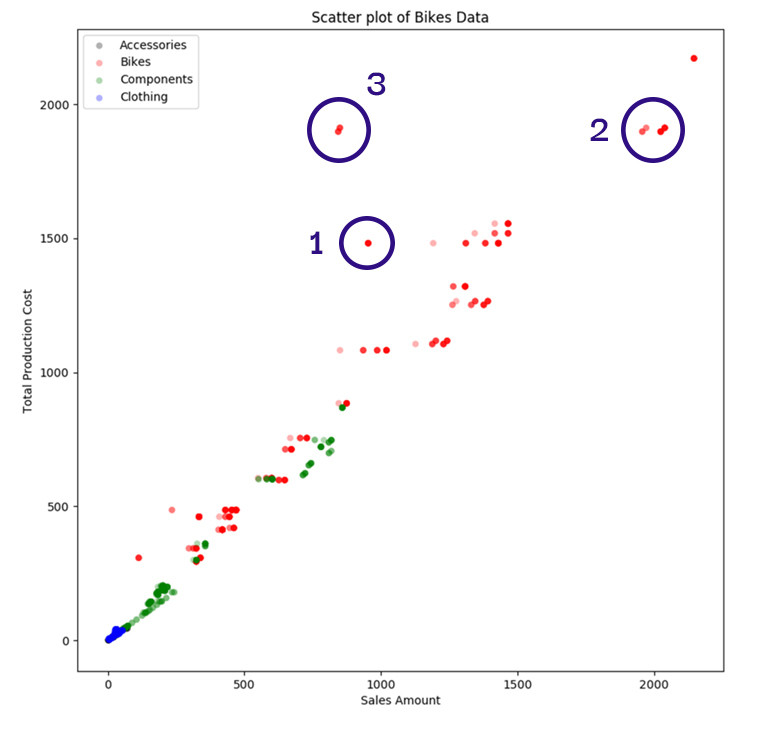
Wenn Sie das obige Schaubild betrachten, werden Sie feststellen, dass bei vielen Produkten die Produktionskosten und die Verkaufsmengen annähernd übereinstimmen. Es gibt einige Produkte, bei denen die Produktionskosten höher sind als der Umsatz, was aus wirtschaftlicher Sicht unerwünscht ist. Einige dieser Produkte sind in dem blauem Kreisen mit der Nummer 1 daneben markiert. Betrachtet man die Punkte in dem mit 2 gekennzeichneten Kreis, so handelt es sich um die Punkte mit den höchsten Herstellungskosten und dem höchsten Verkaufswert. Die Punkte in dem mit 3 gekennzeichneten Kreis haben fast die gleichen Produktionskosten, aber die Verkaufsmenge ist fast halb so hoch, wie bei Gruppe 2. Dies ist also der erste Punkt der Untersuchung für die Ausreißeranalyse.
Wir haben gesehen, dass der von uns verwendete Datensatz mehr als 5000 Punkte enthielt, und das obige Diagramm scheint nicht so viele Punkte zu haben. Der Grund dafür ist, dass viele Produkte genau die gleichen Produktionskosten und den gleichen Umsatz haben können, so dass sich eine Gruppe von Datenpunkten überlagert und wie ein einziger Punkt aussieht. Die Punkte in Kreis 3 erscheinen wie 2 Datenpunkte und die rote Farbe bedeutet, dass es sich um die Kategorie Fahrräder handelt. Lassen wir also die anderen Datenkategorien weg und betrachten wir nur die Daten für Fahrräder.
execute sp_execute_external_script
@language = N'Python',
@script = N'
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
# Create data
colors = (0,0,0)
area = np.pi*3
fig_handle = plt.figure(figsize=(10,10))
plt.scatter(InputDataSet.ExtendedAmount, InputDataSet.TotalProductCost, s=area, c=colors, alpha=0.5)
plt.title("Scatter plot of Bikes Data")
plt.xlabel("Sales Amount")
plt.ylabel("Total Production Cost")
plt.savefig("c:\Test\subcategory-scatterplot_bikes.png")
',
@input_data_1 = N'Select cast(TotalProductCost as float) TotalProductCost, cast(ExtendedAmount as float) ExtendedAmount from MyPythonTestData where EnglishProductCategoryName = ''Bikes'''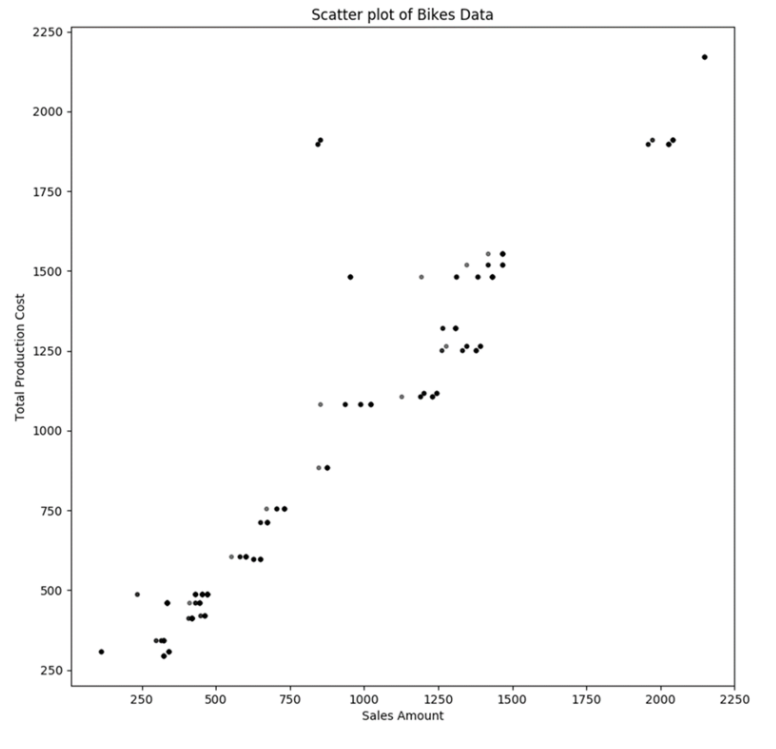
Um die Daten detailliert zu analysieren, wollen wir die Datenpunkte wieder nach Unterkategorien einfärben. Wenden Sie die gleiche Logik, wie bereits im ersten eingefärbten Diagramm auf das neue an, um die Unterkategorien einzufärben und erstellen Sie so ein neues Diagramm. Nun können Sie die Ausreißer zusammen mit ihrer Unterkategorie sofort erkennen.
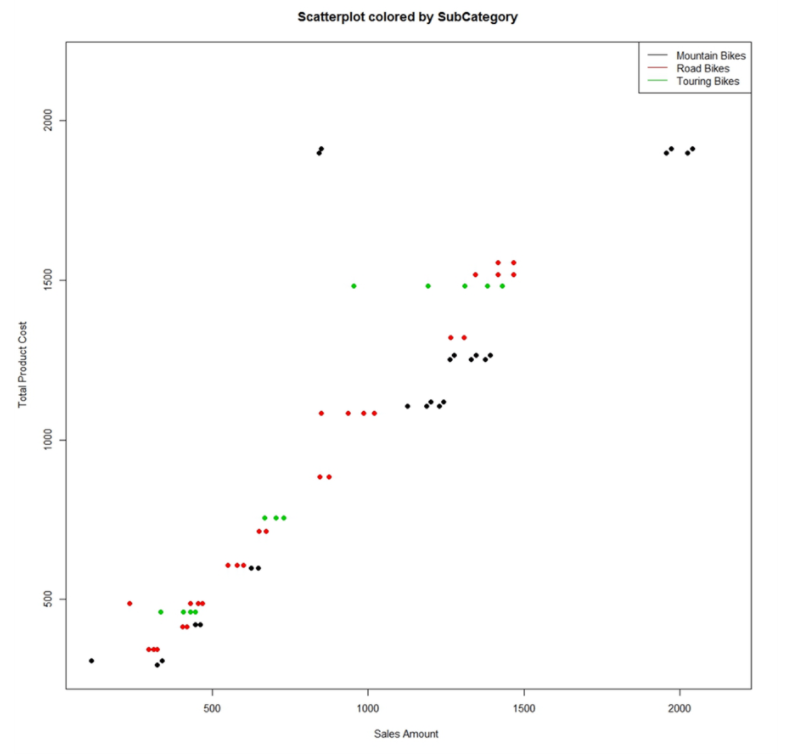
In diesem Diagramm zeigt die schwarze Farbe der Punkte, die wir untersuchen, dass diese Punkte zur Unterkategorie Mountainbikes gehören. Diese Punkte haben Produktionskosten von fast 2000 und einen Umsatz von weniger als 1000. Wenn Sie folgende Abfrage auf den Datensatz ausführen, sollten Sie in der Lage sein, die Ausreißerdaten schnell herauszufinden.
select * from MyPythonTestData
where EnglishProductCategoryName = 'Bikes' and EnglishProductSubcategoryName = 'Mountain Bikes'
AND TotalProductCost > 1500 AND ExtendedAmount < 1000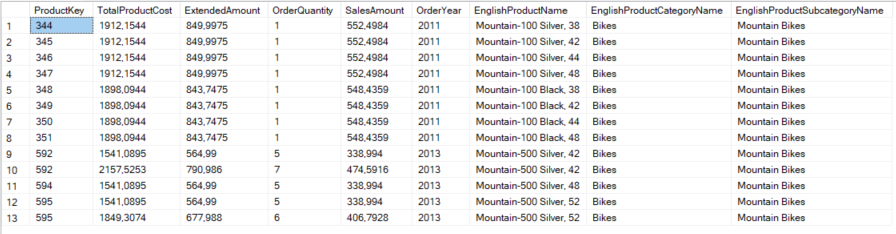
Auf diese Weise konnten wir durch Anwendung der grafischen Analyse in Python visuell vergleichen, wie sich die Produktionskosten nahezu linear auf die Verkaufskosten auswirken. Wir waren in der Lage, alle Produkte proportional zu den Produktionskosten im Verhältnis zur Verkaufsmenge zu vergleichen und die potenziellen Ausreißer visuell zu erkennen. Und schließlich konnten wir genau die gesuchten Ausreißerprodukte ausfindig machen. Sie haben nun anhand ein einfaches Beispiels das Vorgehen bei einer grafischen Analyse mit Python kenngelernt, wobei die tatsächlichen Anwendungen im wirklichen Leben weitaus komplexer, rechenintensiver und umfangreicher sind. Es ist vergleichsweise einfacher, Grafiken in R zu implementieren als in Python.
Python-Skripte als gespeicherte Prozedur
Nicht alle T-SQL-Skripte müssen Python-Skripte verwenden. Auch bei Python-Skripten ist die Wahrscheinlichkeit groß, dass sie komplexe Berechnungen enthalten, die von Datenanalysten/Datenwissenschaftlern/Datenbankentwicklern nach eingehender Analyse entwickelt wurden. Daher ist es ratsam, Python-Skripte nach der Explorations-/Analysephase (siehe oben) in eine gespeicherte Prozedur zu verpacken, um die Logik zu zentralisieren und die Verwaltung zu erleichtern.
Zusammenfassung
In der ersten Lektion unserer Reihe haben wir die Python-Integrationsarchitektur mit SQL Server 2017 analysiert und eine detaillierte Installation, Konfiguration und grundlegende Akzeptanztests von Python mit Tools wie Visual Studio 2017 und SSMS durchgeführt.
Anschließend lernten wir die grundlegenden Programmierkonstrukte von R wie Variablen, Operatoren, Schleifen usw. kennen und haben uns damit beschäftigt, wie man grundlegende Python-Skripte mit T-SQL ausführt. Im Anschluss daran haben wir uns einen Anwendungsfall von Python angesehen, bei dem wir Python zur Berechnung einer Reihe von Statistiken für eine Reihe von Feldern mit einer einzigen Codezeile verwendeten.
In dieser letzten Lektion haben wir gelernt, wie man mit Python aus T-SQL und in SQL Server gespeicherten Daten grafische Visualisierungen erstellt, um eine Analyse mithilfe bestimmter Faktoren durchzuführen. Wir hoffen, dass dieses Tutorial eine gute Ausgangsbasis für alle bietet, die die Möglichkeiten von Python auf SQL Server-Daten anwenden möchten.
Unsere Expert:innen stehen Ihnen bei allen Fragen rund um Ihre IT Infrastruktur zur Seite.
Kontaktieren Sie uns gerne über das
Kontaktformular und vereinbaren ein unverbindliches
Beratungsgespräch mit unseren Berater:innen zur
Bedarfsevaluierung. Gemeinsam optimieren wir Ihre
Umgebung und steigern Ihre Performance!
Wir freuen uns auf Ihre Kontaktaufnahme!
55118 Mainz
info@madafa.de
+49 6131 3331612
Freitags:

