Datentransformation mit Azure Data Analytics

In diesem Artikel geht es um die Datentransformation und Kopieraktivität aus SQL Server Datenbanken in die Azure Data Factory. Explizit erklären wir Ihnen, wie sie mit Hilfe von Azure Synapse Pipelines Datenbanken kopieren und Datenflüsse transformieren. Wir verwenden mitunter den SQL Server Connector, sowie die bereits angesprochene Azure Synapse Pipeline.
Sie können in der Regel Daten aus einer SQL Server Datenbank in jeden unterstützten Senkdatenspeicher kopieren.
Voraussetzung für die Verwendung von SQL Server Connector:
- Sie sollten SQL Server 2005 oder höher verwenden
- Sie sollten eine Windows- oder SQL Authentifizierung besitzen
- Sie sollten über eine Datenquelle in SQL Server verfügen
- Ein automatisches Erstellen einer Zieltabelle (basierend auf dem Quellschema) konfigurieren
Voraussetzung für die Datentransformation:
- Konfigurieren Sie eine selbst gehostete Integrationslaufzeit, sollten sich Ihre Datenspeicher in einem lokalen Netzwerk, virtuellen Azure Netzwerk oder in der Amazon virtual Private Cloud, befinden.
- Verwenden Sie Azure Integration Runtime, wenn Ihr Datenspeicher einem Clouddatendienst zugehörig ist.
- Ist der Zugriff nur auf IPs beschränkt, die über Firewallregeln verfügen, sollten Sie die IPs in der Zulassungsliste von Azure Integration Runtime-IPs ergänzen.
- Verwenden Sie die verwaltete virtuelle Netzwerkintegrationslaufzeit in der Azure Data Factory, um auf das lokale Netzwerk zugreifen zu können. Dafür müssen Sie keine selbst gehostete Integrationslaufzeit installieren und konfigurieren.
Folgende Tools zum Datentransfer via Azure Pipeline können verwendet werden:
- Copy Data Tool
- Azure
- .NET SDK
- Python SDK
- Azure PowerShell
- REST API
- Azure Resource Manager
Start
Erstellen Sie einen SQL Server Dienst. Öffnen Sie das Azure Portal, um einen verknüpften SQL Server Dienst zu erstellen
- Navigieren Sie auf die Registerkarte “Verknüpfte Dienste”.
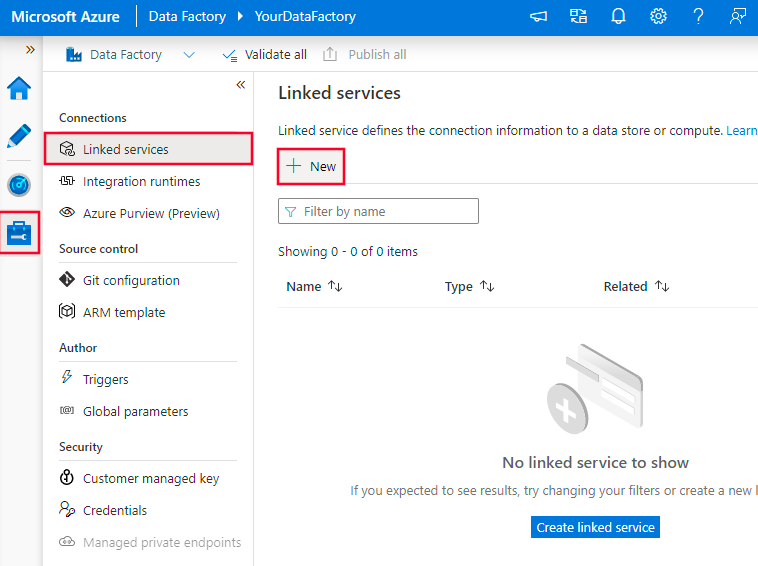
- Suchen Sie nach SQL und wählen Sie den SQL Server Connector aus.

- Konfigurieren Sie die Details des Dienstes und testen Sie die Verbindung.
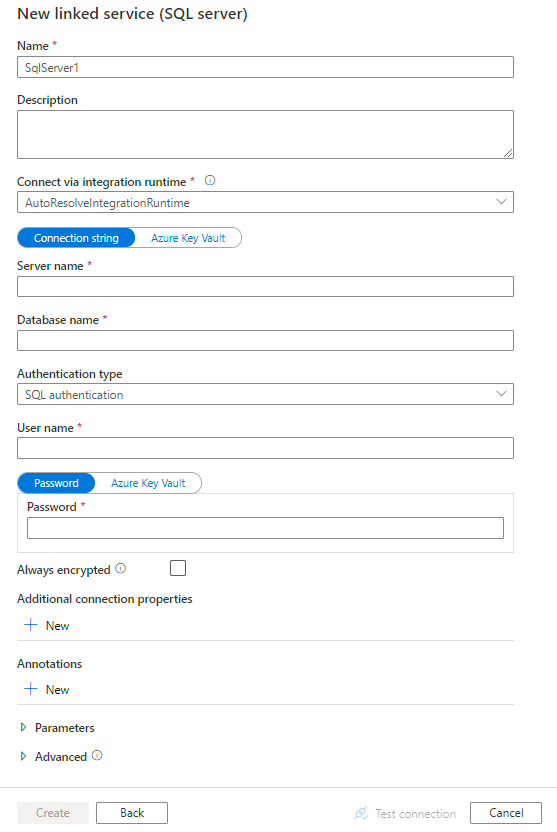
- Voraussetzungen zur Connectorkonfiguration
Type
Die type-Eigenschaft muss auf SQL Server festgelegt werden.
connectionString
Zur Herstellung einer Verbindung zu einer SQL Server Datenbank erfordert eine Windows- oder SQL Authentifizierung. Dafür sollten Sie vorab connectionString Informationen angeben.
Nutzername
Geben Sie einen Benutzernamen an, wenn Sie eine Windows-Authentifizierung verwenden. Beispiel: Domänenname\Benutzername.
Passwort
Geben Sie das dazugehörige Kennwort für das Benutzerkonto an. Markieren Sie dieses Feld als SecureString, um es sicher zu speichern.
AlwaysEncryptedSettings
Durch Angabe der AlwaysEncryptedSettings verschlüsseln Sie sensible Informationen und Daten
connectVia
ConnectVia ist hilfreich zur Herstellung einer Verbindung zum Datenspeicher mit der Integration Runtime. Ist dies nicht konfiguriert, wird die standardmäßige Azure Integrationslaufzeit verwendet.
- SQL Authentifizierung
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"connectionString": "Data Source=<servername>\\<instance name if using named instance>;Initial Catalog=<databasename>;Integrated Security=False;User ID=<username>;Password=<password>;"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}- SQL Authentifizierung mit einem Kennwort in Azure Key Vault
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"connectionString": "Data Source=<servername>\\<instance name if using named instance>;Initial Catalog=<databasename>;Integrated Security=False;User ID=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}- Windows Authentifizierung
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"connectionString": "Data Source=<servername>\\<instance name if using named instance>;Initial Catalog=<databasename>;Integrated Security=True;",
"userName": "<domain\\username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}- AlwaysEncrypted
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"connectionString": "Data Source=<servername>\\<instance name if using named instance>;Initial Catalog=<databasename>;Integrated Security=False;User ID=<username>;Password=<password>;"
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}Datensatzeigenschaften
Folgende Datensatzeigenschaften sollten konfiguriert sein:
Type
Die Type Eigenschaft des Datasets sollte auf SQLServerTable festgelegt sein.
Schema
Geben Sie den Namen des Schemas des Senkdatenspeichers ein.
Tabelle
Geben Sie den Namen des Senkdatenspeichers ein.
Tabellenname
Verwenden Sie den Namen der Tabelle oder das View des Schemas.
{
"name": "SQLServerDataset",
"properties":
{
"type": "SqlServerTable",
"linkedServiceName": {
"referenceName": "<SQL Server linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}SQL Server als Quelle verwenden
Wir stellen Ihnen nun eine Liste an Eigenschaften vor, die von SQL Server Quelle und Senkdatenspeicher unterstützt werden. Um Daten transformieren zu können, muss ein Quelltyp in der Kopieraktivität auf SqlSource festgelegt werden.
| Eigenschaft | Erklärung |
|---|---|
| Type | Die Type-Eigenschaft der Kopieraktivitätsquelle muss in SqlSource festgesetzt werden. |
| sqlReaderQuery | Verwenden Sie benutzerdefinierte SQL Abfragen zum Lesen der Daten. Beispiel: select * from MyTable |
| sqlReaderStoredProcedureName | Diese Eigenschaft ist der Name der gespeicherten Prozedur, die die Daten aus der Quelltabelle liest. Die letzte SQL Anweisung muss eine SELECT Anweisung sein. |
| StoredProcedureParameters | Hier handelt es sich um gespeicherte Parameter der gespeicherten Prozedur. Erlaubte Werte sind Namen oder Wertepaare. Groß- & Kleinschreibung müssen in jedem Fall mit den Parametern der Prozedur übereinstimmen. |
| Isolationslevel | Das Isolationslevel gibt das Transaktionssperrverhalten der SQL Quelle an. Zulässige Werte sind: ReadCommitted, RedUncommitted, RepeatableRead, Serializable, Snapshot. |
| Partitionsoptionen | Gibt die Datenpartitionierungsoptionen an, die zum Laden der Daten von SQL Server verwendet werden. Zulässige Werte sind: None (Standard), PhysicalPartitionsOfTable, DynamicRange. |
| Partitionseinstellungen | Festlegen der Einstellungen für die Datenpartitionierung. |
| partitionColumnName | Gibt den Namen der Quellspalte im Type an, der von der Bereichspartitionierung für die parallele Datenkopie verwendet wird. int, smallint, bigint, date, smalldatetime, datetime, datetime2, datetimeoffset |
| partitionUpperBound | Dies ist der maximale Wert der Partitionsspalte für die Aufteilung des Partitionsbereichs. Dieser Wert wird verwendet, um den Partitionsschritt zu bestimmen. |
| partitionLowerBound | Dies ist der Mindestwert der Partitionsspalte für die Aufteilung des Partitionsbereichs. Auch hier wird der Wert zum Bestimmen des Partitionsschrittes verwendet und stellt den Bereich dar, in dem Zeilen der Tabelle partitioniert und kopiert werden. |
- Wenn sqlReaderQuery für SQLSource angegeben ist, führt die Kopieraktivität die Datenabfrage aus. Sie können des Weiteren auch eine Prozedur angeben mit folgenden Parametern sqlReaderStoredProcedureNameStoredProcedureParameter
- Wenn Sie eine gespeicherte Prozedur in der Quelle verwenden um Daten abzurufen, und diese bei der Übergabe eines anderen Paramaterwerts ein anderes Schema zurückgibt, ist es wichtig darauf zu achten, dass beim Importieren des Schemas aus der Benutzeroberfläche oder beim Kopieren von Datan in die SQL-Datenbank mit automatischer Tabellenerstelleung,Fehler auftreten können.
Sie können dafür folgenden SQL Befehl verwenden:
"activities":[
{
"name": "CopyFromSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]oder alternativ die gespeicherte Prozedur:
"activities":[
{
"name": "CopyFromSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]Hier die Definition der gespeicherten Prozedur:
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GOSQL Server als Senke verwenden
Um Daten in SQL Server zu kopieren, müssen Sie vorab den Senkentyp in der Kopieraktivität auf SqlSink festlegen. Auf folgende Eigenschaften sollten Sie dabei achten:
| Eigenschaft | Erklärung |
|---|---|
| Type | Die Type-Eigenschaft der Kopieraktitivätssenke muss auf SqlSink festgelegt werden. |
| preCopyScript | Diese Eigenschaft gibt die nötige SQL Abfrage an, die ausgeführt werden sollte, bevor Daten kopiert werden. Sie dient vor Allem zur Bereinigung vorab geladener Daten. |
| TableOption | Diese Eigenschaft gibt an, ob die Senkentabelle auf dem Quellschema automatisch erstellt werden soll, wenn sie nicht bereits existiert. |
| sqlWriterStoredProcedureName | Diese Eigenschaft gibt den Namen der gespeicherten Prozedur an, die die Anwendung der Quelldaten auf eine Zieltabelle definiert. |
| StoredProcedureTableTypeParameterName | Der Parametername des in der gespeicherten Prozedur angegebenen Tabellentyps. |
| sqlWriterTabletype | Diese Eigenschaft gibt den in der gespeicherten Prozedur angegebenen Tabellennamen wieder. Die Kopieraktivität stellt die zu kopierenden Daten in einer temporären Tabelle bereit. Der Prozedurcode kann anschließend die kopierten Daten mit vorhandenen Daten verknüpfen. |
| StoredProcedureParameters | Hier finden Sie die Parameter der gespeicherten Prozedur. Erlaubt sind Namen- & Wertepaare, die mit den Werten der gespeicherten Prozedur übereinstimmen müssen. |
| writeBatchSize | Diese Eigenschaft gibt die Anzahl der Zeilen wieder, die pro Batch in die Tabelle eingefügt werden sollen. Standardmäßig bestimmt der Service dynamisch die geeignete Batchgröße. |
| writeBatchTimeout | Hierbei handelt es sich um die Wartezeit für den Abschluss des Batch-Vorgangs. Standardmäßig ist der Wert der Zeitüberschreitung auf 2:00:00 gesetzt. |
| maxConcurrentConnections | Dieser Wert gibt die Obergrenze der gleichzeitigen Verbindungen während der Aktivitätsausführung an. |
Beispiel 1: Daten anhängen
"activities":[
{
"name": "CopyToSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Server output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlSink",
"tableOption": "autoCreate",
"writeBatchSize": 100000
}
}
}
]Beispiel 2: Aufrufen der gespeicherten Prozedur während des Kopiervorgangs
"activities":[
{
"name": "CopyToSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Server output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlSink",
"sqlWriterStoredProcedureName": "CopyTestStoredProcedureWithParameters",
"storedProcedureTableTypeParameterName": "MyTable",
"sqlWriterTableType": "MyTableType",
"storedProcedureParameters": {
"identifier": { "value": "1", "type": "Int" },
"stringData": { "value": "str1" }
}
}
}
}
]Paralleles Kopieren aus der SQL Datenbank
Mit dem SQL Server Connector können Sie von einer integrierten Datenpartitionierung zum parallelen Kopieren von Daten profitieren. Die Datenpartitionierungsoptionen finden Sie im Bereich Source der Kopieraktivität.
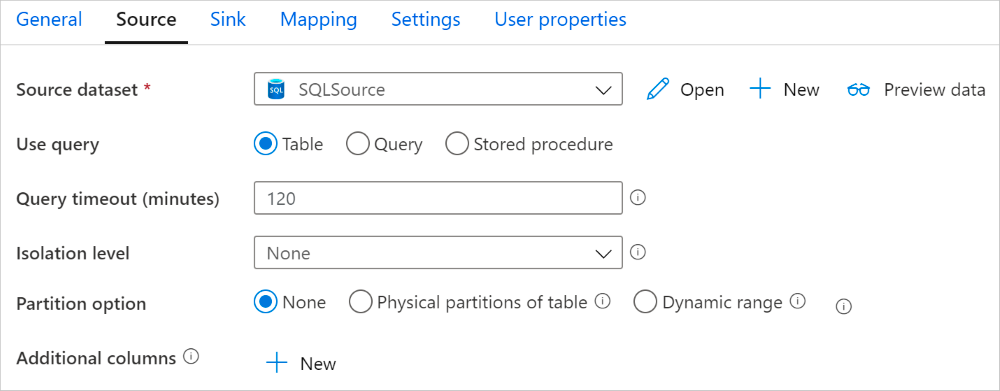
Ist die partitionierte Kopieraktivität aktiviert, führt diese parallele Abfragen für die SQL Server Quelle aus, um Daten nach der Partitionierung zu laden. Der Parallelgrad wird durch die parallelCopies Einstellung bestimmt. Legen Sie den Parallelgrad beispielsweise auf “4” fest, wird der Dienst gleichzeitig 4 Abfragen, basierend auf Ihrer Partitionsoption, durchführen und entsprechende Daten abrufen.
Wir empfehlen das parallele Kopieren mit Datenpartitionierung, wenn Sie über große Datenmengen verfügen. Im Nachgang schlagen wir Ihnen verschiedene Konfigurationsszenarien vor:
| Szenario | Einstellung |
|---|---|
| Vollständige Auslastung einer großen Tabelle mit physischen Partitionen. | Partitionsoption: Physische Partition der Tabelle. Während der Ausführung erkennt der Dienst automatisch die physischen Partitionen und kopiert die Daten entsprechend. |
| Vollständiges Laden von großen Tabellen ohne physische Partitionen | Partitionsoption: Dynamische Bereichspartition Partitionsspalte: Geben Sie die Spalte zum Partitionieren der Daten an. Partitionsober- & untergrenze: Sie können jeweils eine Ober- & Untergrenze der Partitionierung setzen. Ist kein Wert angegeben, werden automatisch alle Zeilen der Tabelle partitioniert und kopiert. |
Laden einer großen Datenmenge mithilfe einer benutzerdefinierten Abfrage ohne physische Partitionen.
Partitionsoption: Dynamische Bereichspartition Abfrage:
SELECT * FROM <TableName> WHERE ? AdfDynamicRangePartitionCondition AND <your_additional_where_clause>Partitionsober- & untergrenze: Sie können jeweils eine Ober- & Untergrenze der Partitionierung setzen. Ist kein Wert angegeben, werden automatisch alle Zeilen der Tabelle partitioniert und kopiert. Während der Ausführung ersetzt der Dienst ?AdfRangePartitionColumnName den tatsächlichen Spaltennamen und die Wertebereiche für jede Partition. Beispielabfragen für verschiedene Szenarien:
-
Abfrage der gesamten Tabelle:
SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition-
Abfrage aus einer Tabelle mit Spaltenauswahl inklusive zusätzlicher WHERE-Klausel:
SELECT <column_list> FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>-
Abfrage mit Unterabfragen:
SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>-
Abfrage mit einer Partition in einer Unterabfrage:
SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition) AS TBest Practices zum Laden von Daten mit der Partitionsoption:
- Wählen Sie eine eindeutige Spalte als Partitionsspalte, um Datenverzerrungen zu vermeiden.
- Wenn die Tabelle über eine integrierte Partition verfügt, sollten Sie zur Leistungsoptimierung die Partitionsoption “physische Partition der Tabelle” verwenden.
- Wenn die Azure Integration Runtime zum Kopieren der Daten verwendet wird, können Sie größere Datenintegrationseinheiten (größer als 4) festlegen, um mehr Rechenressourcen zu nutzen.
- Der Grad der Kopierparallelität kontrolliert die Partitionsnummern. Wir empfehlen den Grad analog der Datenintegrationseinheiten festzulegen.
Beispiel: Laden aus großen Tabellen mit physischen Partitionen
"source": {
"type": "SqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}Beispiel: Abfrage mit einer dynamischen Bereichspartition
"source": {
"type": "SqlSource",
"query": "SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}Beispielabfrage zur Überprüfung der physischen Partition:
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'Verfügt die Tabelle über eine physische Partition, wird die HasPartition mit “yes” angezeigt.
Best Practices zum Laden von Daten in SQL Server
Daten anhängen
Das Anhängen von Daten ist mitunter ein Standardverhalten des SQL Server Senkenconnectors. Dieser Dienst nimmt eine Masseneinführung der Daten durch, um effizient in die Tabelle schreiben zu können.
Daten hochladen
Option 1:
Wenn Sie eine große Datenmenge kopieren müssen, können Sie alle vorhandenen Datensätze mithilfe der Kopieraktivität in eine Staging-Tabelle laden. Führen Sie anschließend eine Stored-Procedure-Aktivität aus, können Sie eine MERGE-, INSERT– oder UPDATE-Anweisung anwenden. Derzeit wird das Laden von Daten in eine temporäre Datenbanktabelle nicht unterstützt. Jedoch gibt es auch den ein oder anderen Tipp, um das zu umgehen. Sie können beispielsweise mittels der Kopieraktivität eine Pipeline erstellen, die mit einer Stored-Procedure-Aktivität verknüpft ist. Es werden zunächst Daten aus Ihrem Quellspeicher in eine SQL Server Stagingtabelle kopiert. Danach wird die gespeicherte Prozedur aufgerufen, die die Daten aus dem Quellspeicher und der Stagingtabelle in einer Zieltabelle zusammenfasst.
Definieren Sie in Ihrer Datenbank eine MERGE-Logik, wird aus der vorherigen Aktivität auf die gespeicherte Prozedur verwiesen.
CREATE PROCEDURE [dbo].[spMergeData]
AS
BEGIN
MERGE TargetTable AS target
USING UpsertStagingTable AS source
ON (target.[ProfileID] = source.[ProfileID])
WHEN MATCHED THEN
UPDATE SET State = source.State
WHEN NOT matched THEN
INSERT ([ProfileID], [State], [Category])
VALUES (source.ProfileID, source.State, source.Category);
TRUNCATE TABLE UpsertStagingTable
ENDOption 2:
Sie können eine gespeicherte Prozedur innerhalb einer Kopieraktivität aufrufen. Hier wird anders zur Option 1 keine Masseneinführung durchgeführt. Jeder Batch wird einzeln in der Quelltabelle ausgeführt.
Die gesamte Tabelle überschreiben
Mit der preCopyScript Eigenschaft können Sie eine gesamte Tabelle überschreiben. Die Eigenschaft kann innerhalb einer Kopieraktivitätssenke konfiguriert werden und führt entsprechendes Skript zum Löschen der Datensätze zuerst aus.
Schreiben Sie Daten mit benutzerdefinierter Logik
Das Schreiben von Daten mit einer benutzerdefinierten Logik entspricht dem Vorgang des Daten-Hochladens. Wenn Sie vor dem Einfügen der Quelldaten in eine Zieltabelle eine Verarbeitung vornehmen müssen, können Sie auch einfach eine Stagingtabelle laden und die Aktivität mit einer gespeicherten Prozedur aufrufen.
Aufrufen der Prozedur aus einer SQL Senke heraus
Wenn Sie Daten in eine SQL Server Datenbank kopieren, können Sie eine individuelle gespeicherte Prozedur mit zusätzlichen Parametern für jeden Batch konfigurieren und aufrufen. Dieses Feature nutzt einen Tabellenwertparameter. Beachten Sie jedoch, dass der Dienst die Prozedur automatisch in eine eigene Transaktion umwandelt, sodass die innerhalb der gespeicherten Prozedur erstelle Transaktion zu einer verschachtelten Transaktion wird. Dies kann Auswirkungen auf die Ausnahmebehandlung haben.
Verwenden Sie die gespeicherte Prozedur nur, wenn bereits konfigurierte Kopiermechanismen nicht ihren Zweck erfüllen und Ihnen die Arbeit erschweren.
Im folgenden Beispiel zeigen wir Ihnen, wie Sie eine gespeicherte Prozedur verwenden, um einen Datenupload in einer SQL Server Datenbank vorzunehmen:
- Definieren Sie in Ihrer Datenbank den Tabellentyp mit demselben Namen wie sqlWriterTableType. Das Schema des Tabellentyps entspricht dem Schema, der von Ihren Eingabedaten zurückgegeben wird.
CREATE TYPE [dbo].[MarketingType] AS TABLE( [ProfileID] [varchar](256) NOT NULL, [State] [varchar](256) NOT NULL, [Category] [varchar](256) NOT NULL )- Definieren Sie in Ihrer Datenbank die gespeicherte Prozedur mit demselben Namen wie sqlWriterStoredProcedureName. Sie verarbeitet Eingabedaten aus der angegebenen Quelle und führt sie in die Ausgabetabelle ein. Der Parametername des Tabellentyps entspricht dem im Dataset definierten tableName.
CREATE PROCEDURE spOverwriteMarketing @Marketing [dbo].[MarketingType] READONLY, @category varchar(256)
AS
BEGIN
MERGE [dbo].[Marketing] AS target
USING @Marketing AS source
ON (target.ProfileID = source.ProfileID and target.Category = @category)
WHEN MATCHED THEN
UPDATE SET State = source.State
WHEN NOT MATCHED THEN
INSERT (ProfileID, State, Category)
VALUES (source.ProfileID, source.State, source.Category);
END- Definieren Sie den Abschnitt SQL-Senke in der Kopieraktivität:
"sink": {
"type": "SqlSink",
"sqlWriterStoredProcedureName": "spOverwriteMarketing",
"storedProcedureTableTypeParameterName": "Marketing",
"sqlWriterTableType": "MarketingType",
"storedProcedureParameters": {
"category": {
"value": "ProductA"
}
}
}Datenfluss-Eigenschaften definieren
Beim Transformieren von Daten im Mapping-Datenfluss können Sie Tabellen aus der SQL Server Datenbank lesen und diese auch schreiben. Eine Voraussetzung für den Zugriff auf SQL Server ist eine konfigurierte Azure Data Factory oder ein von Azure Synapse Workspace verwaltetes virtuelles Netzwerk.
Quelltransformation
| Name | Beschreibung | zulässige Werte |
|---|---|---|
| Tabelle | Wählen Sie Tabelle als Eingabe aus, ruft der Datenfluss alle Daten aus der im Datensatz angegebenen Tabelle ab. | / |
| Anfrage | Mit Abfrage rufen Sie Daten aus der Quelle ab, die alle Tabellen überschreiben, die im Dataset angegeben sind. Die Abfrage eignet sich bestens zum Testen von Zeilen. Die ORDER-BY Klausel wird allerdings nicht unterstützt. Sie können alternativ jedoch eine vollständige SELECT-FROM Klausel verwenden, die eine passende Tabelle zurückgibt, die Sie im Datenfluss verwenden können. | Zeichenfolge |
| Losgröße | Geben Sie eine Batchgröße an, um große Datenmengen in einzelne Lesevorgänge zu unterteilen. | Ganze Zahlen |
| Isolationsstufe | Wählen Sie eine der folgenden Isolationsstufen: Read CommittedRead Uncommitted (Standard)Repeatable ReadSerializable None (Isolationsstufe ignorieren) | READ_COMMITTEDREAD_UNCOMMITTEDREPEATABLE_READSERIALIZABLENONE |
Beispiel für ein SQL Server Quellskript
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from MYTABLE',
format: 'query') ~> SQLSourceEigenschaften der Senkentransformation
| Name | Beschreibung | Zulässige Werte |
|---|---|---|
| Update-Methode | Die Update-Methode gibt an, welche Operationen auf Ihrem Datenbankziel zulässig sind. Standardisiert sind nur Einfügungen zulässig. | true false |
| Schlüsselspalten | Um Aktualisierungen, Uploads und Löschungen vorzunehmen, müssen Schlüsselspalten festgelegt sein. Sie bestimmen, welche Zeile geändert werden soll. | Array |
| Schreiben von Schlüsselspalten überspringen | Sie können den Wert in der Schlüsselspalte überspringen. | true false |
| Tabellenaktion | Die Tabellenaktion bestimmt, ob alle Zeilen vor dem Schreiben neu erstellt oder aus der Zieltabelle entfernt werden müssen. None: An der Tabelle wird keine Aktion ausgeführt New: Die Tabelle wird gelöscht und neu erstellt. Truncate: Alle Zeilen werden aus der Zieltabelle entfernt. | true false |
| Losgröße | Die Losgröße gibt an, wie viele Zeilen pro Batch geschrieben werden. Eine hohe Anzahl an Batchgrößen verbessern die Komprimierung und Speicheroptimierung, riskieren jedoch beim Zwischenspeichern einen Speichermangel. | Ganze Zahlen |
| Pre- & Post SQL Skripte | Geben Sie mehrzeilige SQL Skripte an, bevor und nachdem Sie Daten in Ihre Sink-Datenbank schreiben. | Zeichenfolge |
Beispiel für ein SQL Server Senkenskript:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SQLSinkDatentypzuordnung für SQL Server
Wenn Sie Daten von und zu SQL Server transferieren, werden folgende Zuordnungen geändert.
| SQL Server Datentyp | Azure Data Factory Datentyp |
|---|---|
| bigint | Int64 |
| binary | Byte |
| bit | Boolean |
| char | String, Char |
| date | DateTime |
| Datetime | DateTime |
| Datetime2 | DateTime |
| Datetimeoffset | DateTimeOffset |
| Decimal | Decimal |
| FILESTREAM attribute | Byte |
| Float | Double |
| image | Byte |
| int | Int32 |
| money | Decimal |
| nchar | String, Char |
| ntext | String, Char |
| numeric | Decimal |
| nvchar | String, Char |
| real | Single |
| rowversion | Byte |
| smalldatetime | DateTime |
| smallint | Int16 |
| smallmoney | Decimal |
| sql_variant | Object |
| text | Sting, Char |
| time | TimeSpan |
| timestamp | Byte |
| tinyint | Int16 |
| uniqueidentifier | Guid |
| varbinary | Byte |
| varchar | Sting, Char |
| xml | Sting |
Verwenden von Always Encrypted
Kopieren Sie Daten von oder nach SQL Server, sollten Sie sicherheitshalber mit Always Encrypted kopieren und folgende Schritte beachten:
- Speichern Sie den Spaltenhauptschlüssel in einem Azure Key Vault.
- Stellen Sie sicher, dass Sie einen Zugriff auf den Schlüsseltresor gewähren, in dem der Column Master Key gespeichert ist.
- Stellen Sie eine Verbindung zu einer SQL Datenbank her und aktivieren Always Encrypted. Dafür sollten Sie entweder die verwaltete Identität oder einen Dienstprinzipal verwenden.
SQL Server Always Encrypted unterstützt folgende Szenarien:
- Quell- oder Senkdatenspeicher verwenden einen verwaltete Identität oder einen Dienstprinzipal als Schlüssel-Authentifizierungstyp.
- Sowohl Quell- & Senkdatenspeicher verwenden die verwaltete Identität als Schlüssel-Authentifizierungstyp.
- Sowohl Quell- & Senkdatenspeicher verwenden denselben Dienstprinzipal als Schlüssel-Authentifizierungstyp.
Verbindungsprobleme beheben
- Um Verbindungsprobleme zu beheben, konfigurieren Sie Ihre SQL Server Instanz so, dass Remoteverbindungen zugelassen werden können.
- Starten Sie das SQL Server Management Studio (SSMS) und wählen mit der rechten Maustaste Server und Properties.
- Wählen Sie die Verbindungen aus der Liste aus und aktivieren das Kontrollkästchen um die Remoteverbindungen zu diesem Server zuzulassen.
- Starten Sie den SQL Server Konfiguationsmanager und erweitern Sie die SQL Server Netzwerkkonfiguration für die gewünschte Instanz.
- Wählen Sie dafür die Protokolle für MSSQLSERVER aus. Diese werden Ihnen im rechten Bereich angezeigt.
- Aktivieren Sie TCP/IP durch einen Rechtsklick.
- Durch einen Doppelklick auf TCP/IP können Sie die Eigenschaften öffnen.
- Wechseln Sie auf die Registerkarte IP-Adressen und scrollen zum Abschnitt IPAII.
- Notieren Sie sich den TCP-Port. Standardmäßig liegt dieser bei 1433.
- Erstellen Sie eine Regel für die Windows Firewall, um den Datenverkehr über den TCP Port zuzulassen.
- Überprüfen Sie die Verbindung im SSMS über den Befehl:
<machine>.<domain>.corp.<company>.com,1433In diesem umfangreichen Artikel haben wir Ihnen diverse Formen der Datentransformation mit Azure Synpase vorgestellt. Gerne stehen wir Ihnen bei Rückfragen über unser Kontaktformular jederzeit zur Verfügung.
Unsere Expert:innen stehen Ihnen bei allen Fragen rund um Ihre IT Infrastruktur zur Seite.
Kontaktieren Sie uns gerne über das
Kontaktformular und vereinbaren ein unverbindliches
Beratungsgespräch mit unseren Berater:innen zur
Bedarfsevaluierung. Gemeinsam optimieren wir Ihre
Umgebung und steigern Ihre Performance!
Wir freuen uns auf Ihre Kontaktaufnahme!
55118 Mainz
info@madafa.de
+49 6131 3331612
Freitags:

