Automatic Seeding in Always On-Verfügbarkeitsgruppen

Einführung
Um ein sekundäres Replikat in SQL Server 2012 und 2014 in einer Always-On-Verfügbarkeitsgruppe zu initialisieren ist die Verwendung von Sicherungen, Kopien und Wiederherstellungen notwendig. Mit SQL Server 2016 ist die neue Funktion zum Initialisieren eines sekundären Replikats eingeführt worden – das automatische Seeding.
In SQL Server Always On Availability Groups können wir eine Datenbank mit verschiedenen Methoden zu einer bestehenden Verfügbarkeitsgruppe hinzufügen. Im Assistenten für die anfängliche Datensynchronisierung in SSMS erhalten wir die folgende Option.
-
Vollständige Datenbank- und Protokollsicherung: Die Datensynchronisierung beginnt mit der Erstellung von Voll- und Protokollsicherungen für die Datenbank der Verfügbarkeitsgruppe. Diese Sicherungen werden in jedem sekundären Replikat wiederhergestellt und mit der Verfügbarkeitsgruppe verbunden.
-
Join Only: Wenn wir manuelle Backups erstellt und auf dem sekundären Server wiederhergestellt haben, können wir die Join-Only-Methode verwenden, um eine Datenbank zu einer Verfügbarkeitsgruppe hinzuzufügen.
-
Initiale Datensynchronisierung überspringen: Wenn alle Datenbanksicherungen manuell durchgeführt, auf jedem sekundären Replikat wiederhergestellt und manuell auf dem sekundären Replikat verbunden werden sollen, kann diese Option gewählt werden.
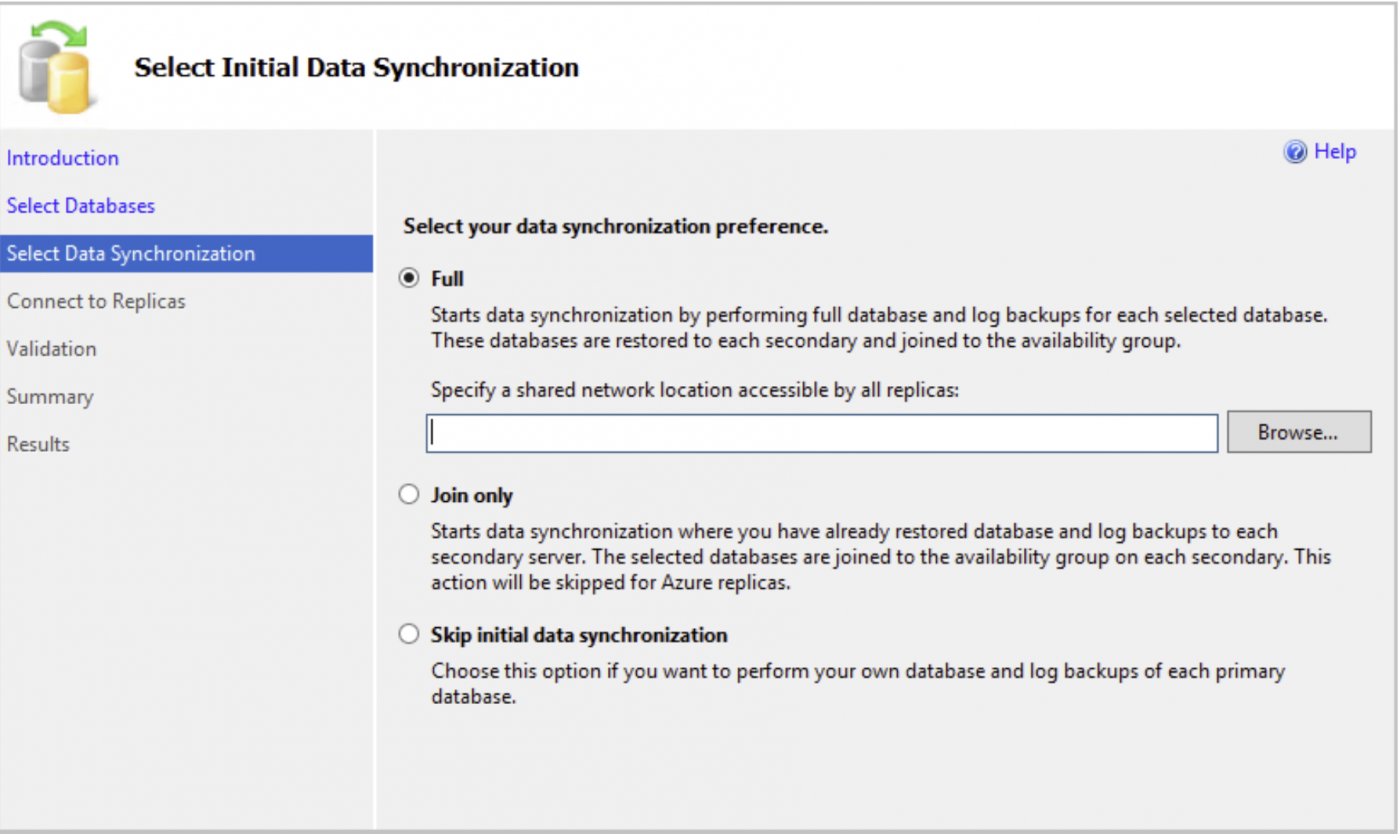
In der Regel folgen DBAs der Join Only-Methode, nachdem die Backups manuell auf jeder sekundären Replik wiederhergestellt wurde. Dieser Ansatz ist auch für große Datenbanken geeignet.
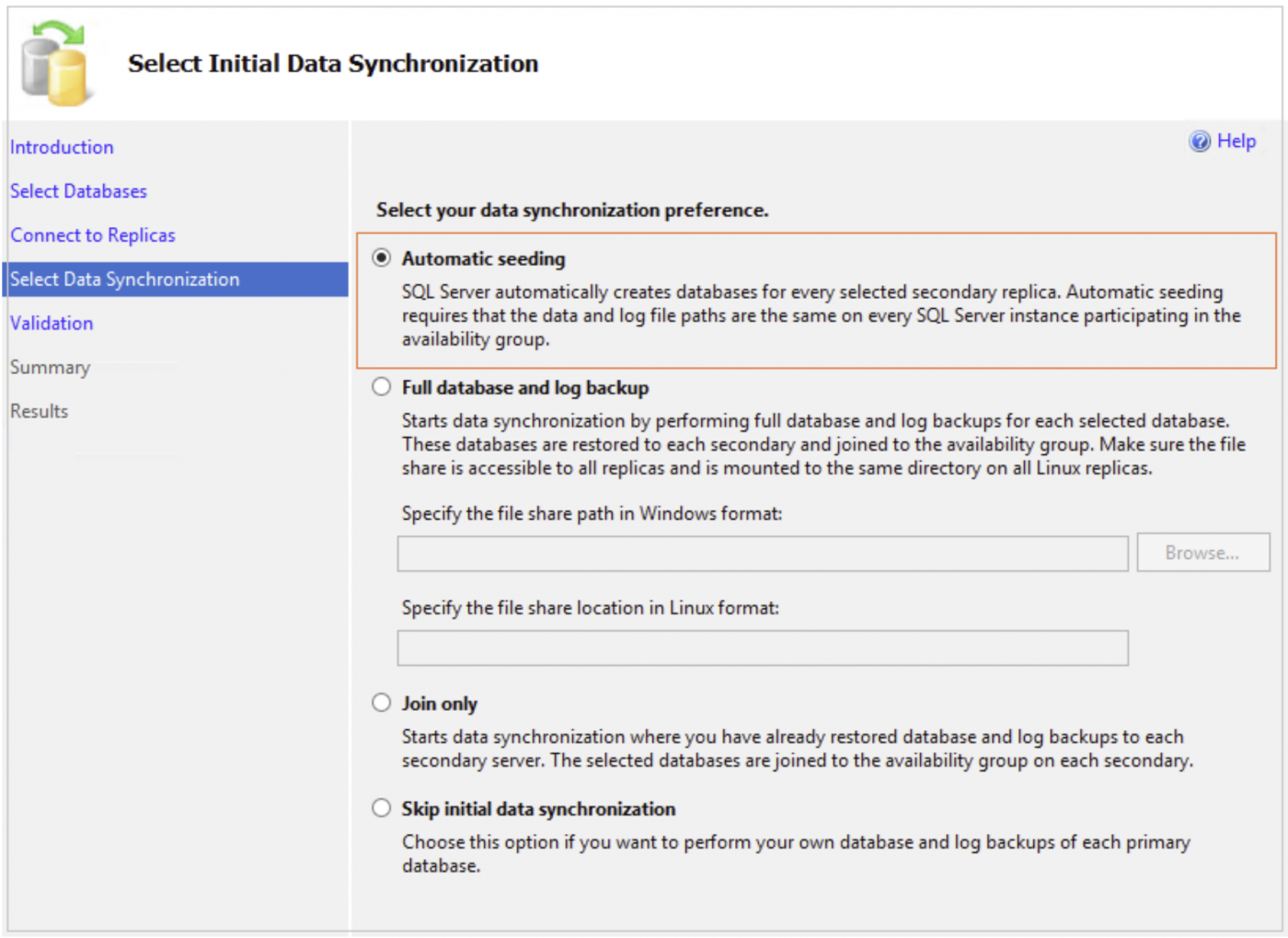
SQL Server 2016 führte eine neue Datensynchronisationsmethode für Datenbanken in Always On Availability Groups ein - Automatic Seeding oder Direct Seeding
Sie müssen SQL Server 2016 oder höher mit SQL Server Management Studio 17.4 oder höher verbinden, um diese Option zu sehen. Sie können diese Funktion noch mit der alten SSMS-Version verwenden, aber nicht mit der GUI-Methode. Wir empfehlen Ihnen, die neueste SSMS-Version zu installieren.
Aktivieren der Trace-Flags für die Komprimierung im automatischen Seeding für Always On Availability Groups
Standardmäßig ist die Komprimierung für das automatische Seeding-Streaming nicht aktiviert. Wir können die Trace-Flag 9657 nutzen, um die Komprimierung zu aktivieren. Sie ist vor allem für große Datenbanken geeignet. Sie werden möglicherweise einen Anstieg der CPU-Leistung der primary replica feststellen.
Wir können diese Trace-Flag entweder als Startparameter oder mit dem Befehl DBCC TRACEON aktivieren. Führen Sie den folgenden Befehl aus, um das Trace-Flag auf globaler Ebene zu aktivieren.
DBCC TRACEON (9567,-1)Wenn Sie einen Startparameter hinzufügen möchten, gehen Sie zum SQL Server-Konfigurationsmanager und öffnen Sie die Eigenschaften des SQL Server-Dienstes. Gehen Sie im Eigenschaftsfenster zum Startparameter und fügen Sie die Trace-Flag hinzu.
Hinzufügen einer Datenbank in AG mit automatischem Seeding für Always On Availability Groups
Mit den folgenden Schritten können wir eine Datenbank in SQL Server Always On mit Automatic Seeding hinzufügen.
Verbinden Sie sich mit dem primary replica, klicken Sie mit der rechten Maustaste auf die Verfügbarkeitsgruppe und klicken Sie auf Datenbank hinzufügen. Daraufhin wird ein Assistent zum Hinzufügen der Datenbank zu einer Verfügbarkeitsgruppe gestartet.
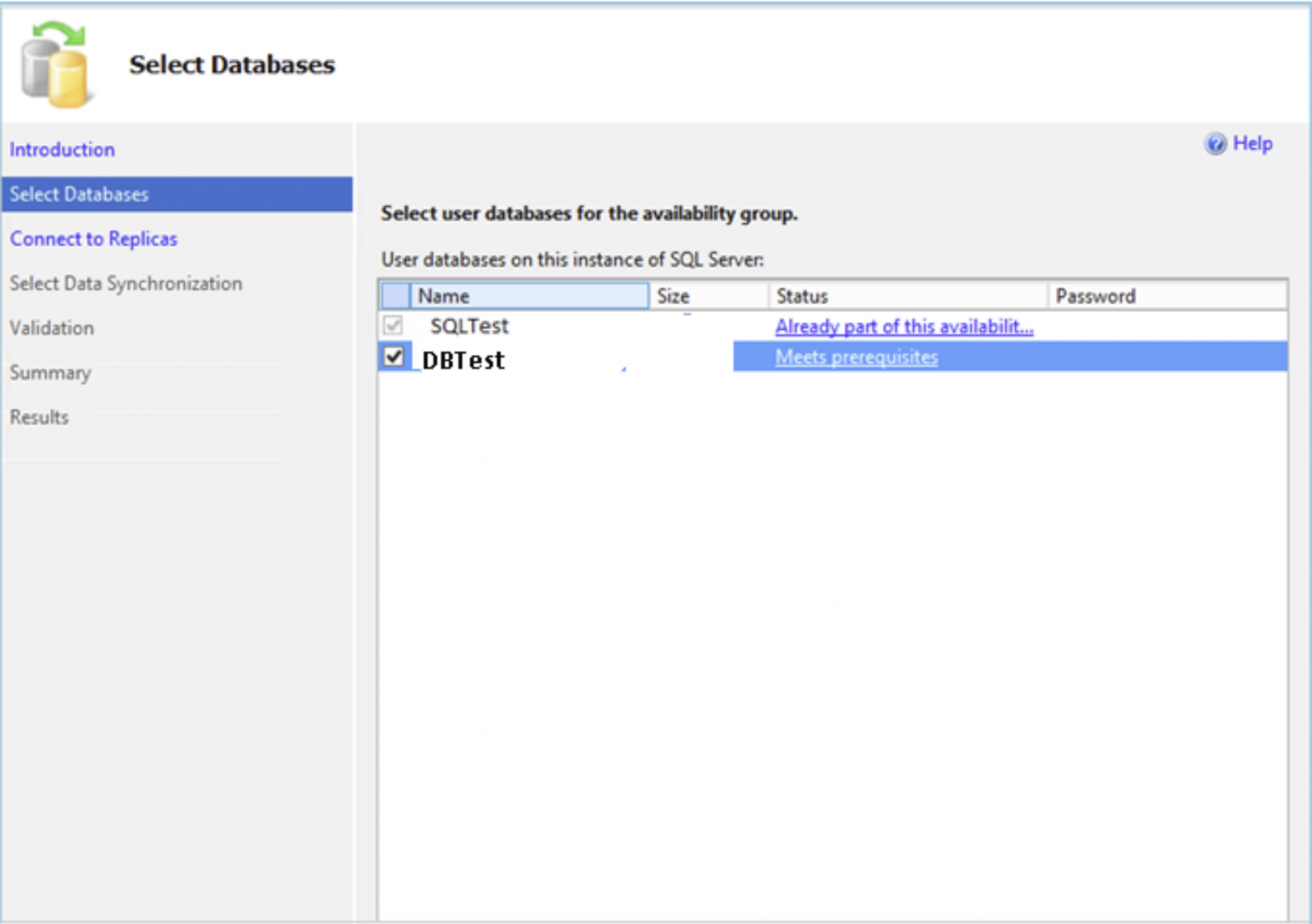
Klicken Sie auf Weiter und wählen Sie eine Datenbank aus, die der bestehenden Verfügbarkeitsgruppe hinzugefügt werden soll. Diese Datenbank sollte ein vollständiges Backup haben, um die Voraussetzung für die Always On Availability Groups zu erfüllen.
Stellen Sie auf dem nächsten Bildschirm eine Verbindung zu Ihrem second replica her und wählen Sie für die anfängliche Datensynchronisierung die Option Automatisches Seeding.
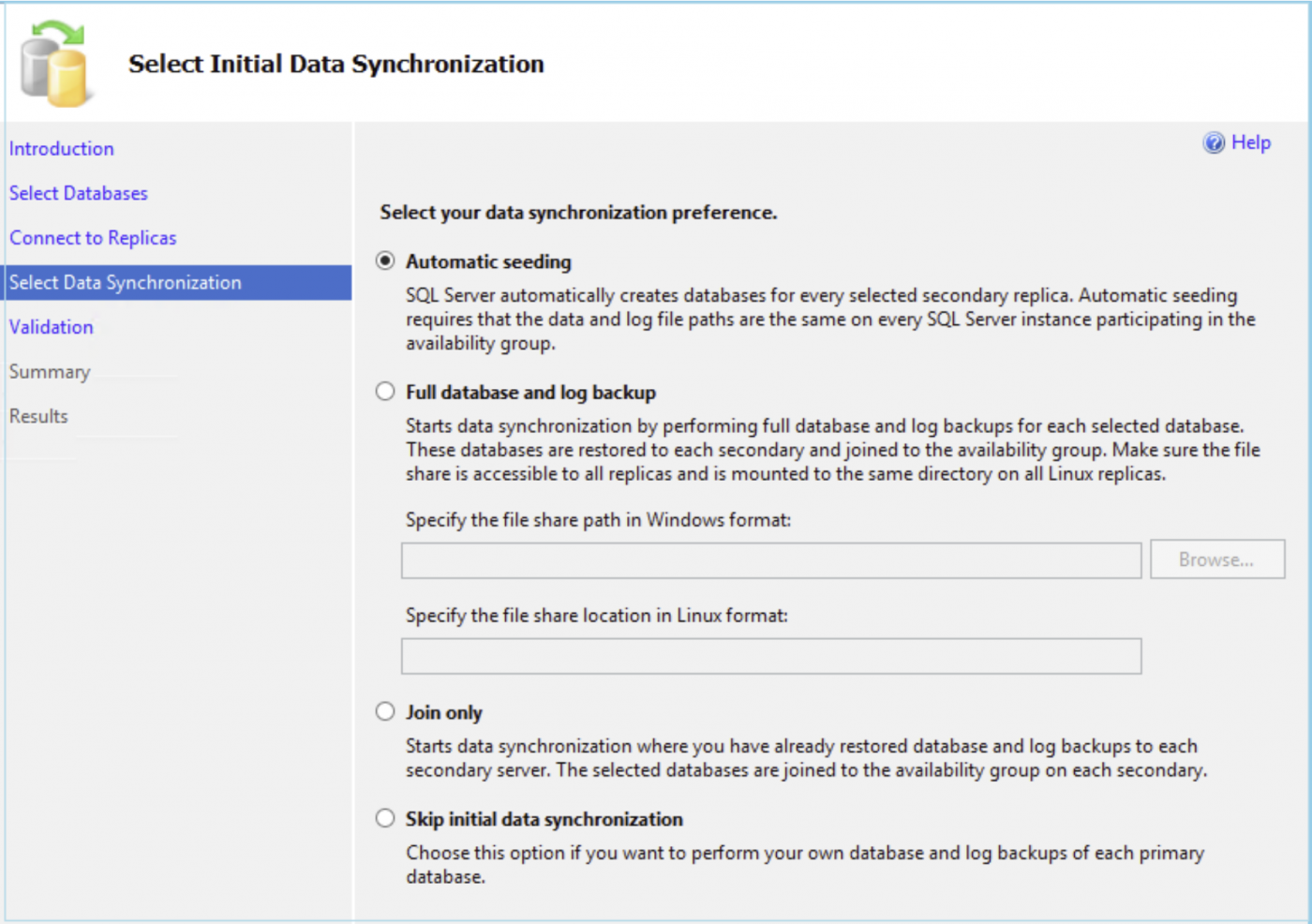
Die Verzeichnisse auf dem primären und allen sekundären Replikaten sollten übereinstimmen. Wenn die Verzeichnisse nicht übereinstimmen oder in den sekundären Replikaten nicht vorhanden sind, erhalten Sie die folgende Fehlermeldung.
The following required directories do not exist on replica DBTest : D:\DBTest,D:\DBTest. (Microsoft.SqlServer.Management.HadrModel)
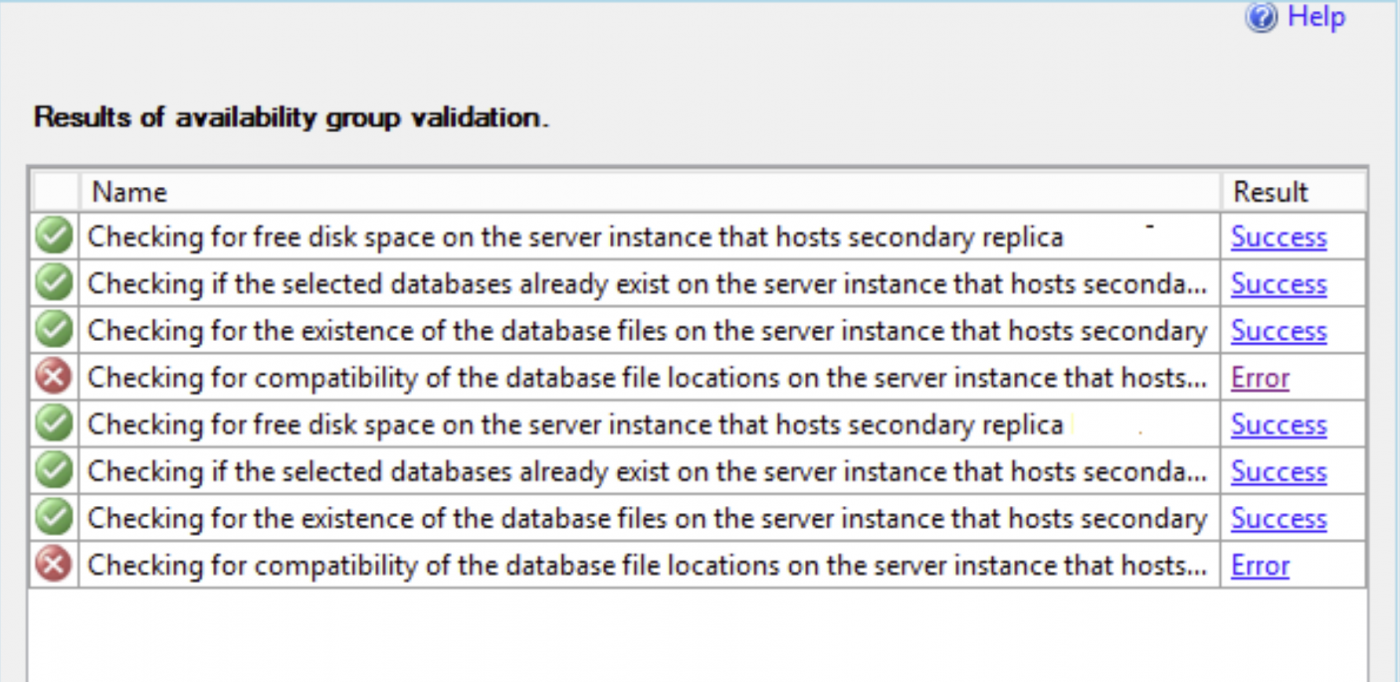
Auch in der sekundären Replik sollte ausreichend freier Speicherplatz für die Datenbankkopie vorhanden sein, ähnlich wie in der primären Replik von Always On Availability Groups.
Wenn in der sekundären Replik Probleme auftreten, erhalten Sie eine Fehlermeldung. Sie sollten den Fehler beheben und die Validierung erneut durchführen.
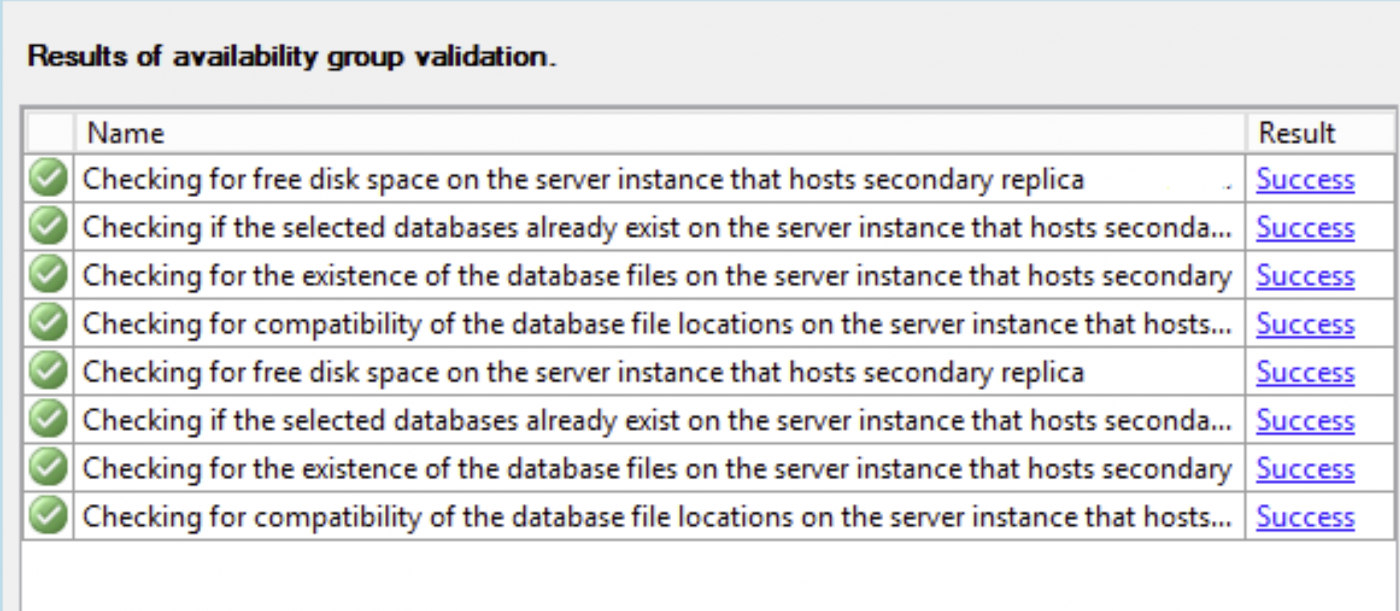
Wenn alle Überprüfungen für jedes sekundäre Replikat erfolgreich waren, klicken Sie auf Weiter und eine Datenbank wird der Verfügbarkeitsgruppe hinzugefügt. Sie erhalten die folgende Meldung.
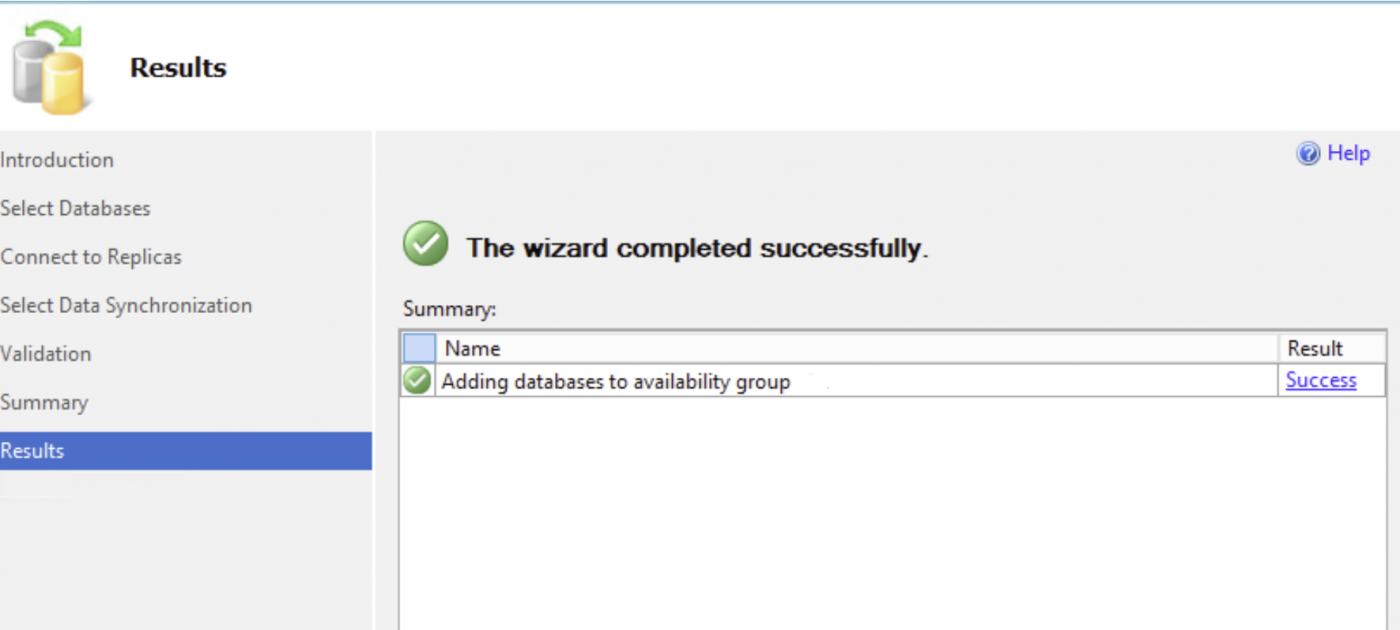
Die Synchronisierung kann je nach Datenbankgröße, Netzwerkbandbreite, Festplattengeschwindigkeit usw. einige Zeit dauern. Sie sollten den Status des automatischen Seedings überwachen, insbesondere bei großen Datenbanken.
Internes automatisches Seeding und Monitoring in Always On Availability Groups
SQL Server führt die folgenden Schritte aus, um eine Datenbank mit Automatic Seeding hinzuzufügen.
- SQL Server führt eine vollständige Datenbanksicherung mit der Microsoft SQL Server Virtual Device Interface (VDI)-Volldatenbank durch.
- Diese VDI-Datenbanksicherung wird über das Netzwerk an alle verfügbaren sekundären Replikate gestreamt.
- Die sekundäre Replik stellt diese gestreamte Sicherung wieder her.
- Sobald die Wiederherstellung der Datenbank abgeschlossen ist, wird sie der Verfügbarkeitsgruppe hinzugefügt.
Normalerweise überprüfen wir den Status der Datenbanksicherung mit dem DMV sys.dm_exec_requests. Wenn Sie diesen Befehl auf der primären Replik ausführen und nach dem für die Sicherung spezifischen Befehl suchen, erhalten Sie keine Ausgabe für die Sicherung.
Da es sich um eine VDI-Sicherung handelt, müssen Sie den folgenden Befehl auf der primären Replik ausführen, um den Status der Sicherung zu überprüfen.
SELECT
r.session_id, r.status, r.command, r.wait_type
, r.percent_complete, r.estimated_completion_time
FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s
ON r.session_id = s.session_id
WHERE r.session_id <> @@SPID
AND s.is_user_process = 0
AND r.command like 'VDI%'
and wait_type ='BACKUPTHREAD'Im folgenden Screenshot sehen Sie, dass der Befehl VDI_Client_WORKER die Sicherung ausführt und Sie können den prozentualen Abschluss der Sicherung verfolgen.

Auf dem sekundären Replikat von Always On Availability Groups können Sie den folgenden Befehl ausführen, um den Status des REDO-Vorgangs zu überprüfen.
SELECT
r.session_id, r.status, r.command, r.wait_type
, r.percent_complete, r.estimated_completion_time
FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s
ON r.session_id = s.session_id
WHERE r.session_id <> @@SPID
AND s.is_user_process = 0
AND r.command like 'REDO%'
and wait_type ='BACKUPTHREAD'Sehen wir uns ein paar andere Methoden zur Überwachung des automatischen Seedings an.
Dynamische Verwaltungsansichten
Mit den folgenden dynamischen Verwaltungsansichten können Sie den Fortschritt des Automatic Seeding für Always On Availability Groups überwachen:
-
Sys .dm_hard_automatic_seeding: Diese DMV dient als Zusammenfassung aller erfolgreichen und fehlgeschlagenen automatischen Seeding-Informationen für jede Datenbank und jedes Replikat. Bei mehreren Versuchen werden die Wiederholungsversuche gezählt. Außerdem werden die zugehörigen Fehler- und Misserfolgscodes angezeigt, falls das automatische Seeding fehlgeschlagen ist.
-
Sys .dm_hard_physical_seeding_stats: Dieser DMV ist nützlich, um den aktuellen Status des automatischen Seeding zu ermitteln, einschließlich der Übertragungsrate, der geschätzten Fertigstellungszeit, der Datenbankgröße und der aktivierten oder nicht aktivierten Komprimierung
Führen wir nun den DMV aus, um den Seeding-Status des primären Replikats zu überprüfen.
select local_database_name
, remote_machine_name,role_desc ,internal_state_desc
,transfer_rate_bytes_per_second/1024/1024 as transfer_rate_MB_per_second ,transferred_size_bytes/1024/1024 as transferred_size_MB
,database_size_bytes/1024/1024/1024/1024 as Database_Size_TB,
is_compression_enabled from sys.dm_hadr_physical_seeding_statsIm folgenden Screenshot sehen Sie, dass zwei Zeilen zurückgegeben werden. Ich habe drei Knoten der Always On Availability Groups in meiner Umgebung. SQL Server überträgt die Streaming-Sicherung an die beiden sekundären Replikate. Wir können sehen, dass is_compress_enabled auf 1 gesetzt ist, was zeigt, dass die Trace-Flag 9567 für die Komprimierung aktiviert ist.

Windows Performance Monitor
Sie können auch den Performance Monitor verwenden, um Informationen über die Netzwerkgeschwindigkeit während des automatischen Seedings zu erhalten. Verwenden Sie auf dem primären Replikat den Parameter Bytes sent per second, um die Netzwerkgeschwindigkeit zu überprüfen.
Gesendete Bytes pro Sekunde auf der primären Replik
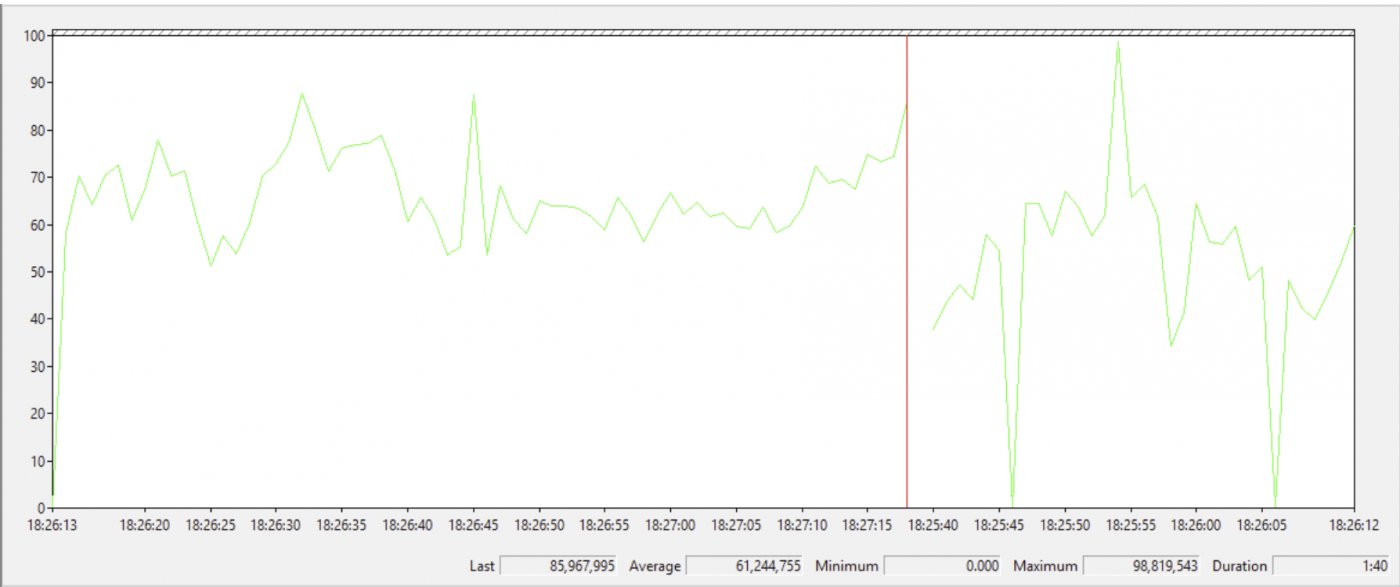
In ähnlicher Weise können wir für eine sekundäre Replik in Always On-Verfügbarkeitsgruppen den Leistungsparameter "Bytes received per second" verwenden, um die Netzwerkgeschwindigkeit am Ende der sekundären Replik zu überprüfen.
Empfangene Bytes pro Sekunde auf der sekundären Replik
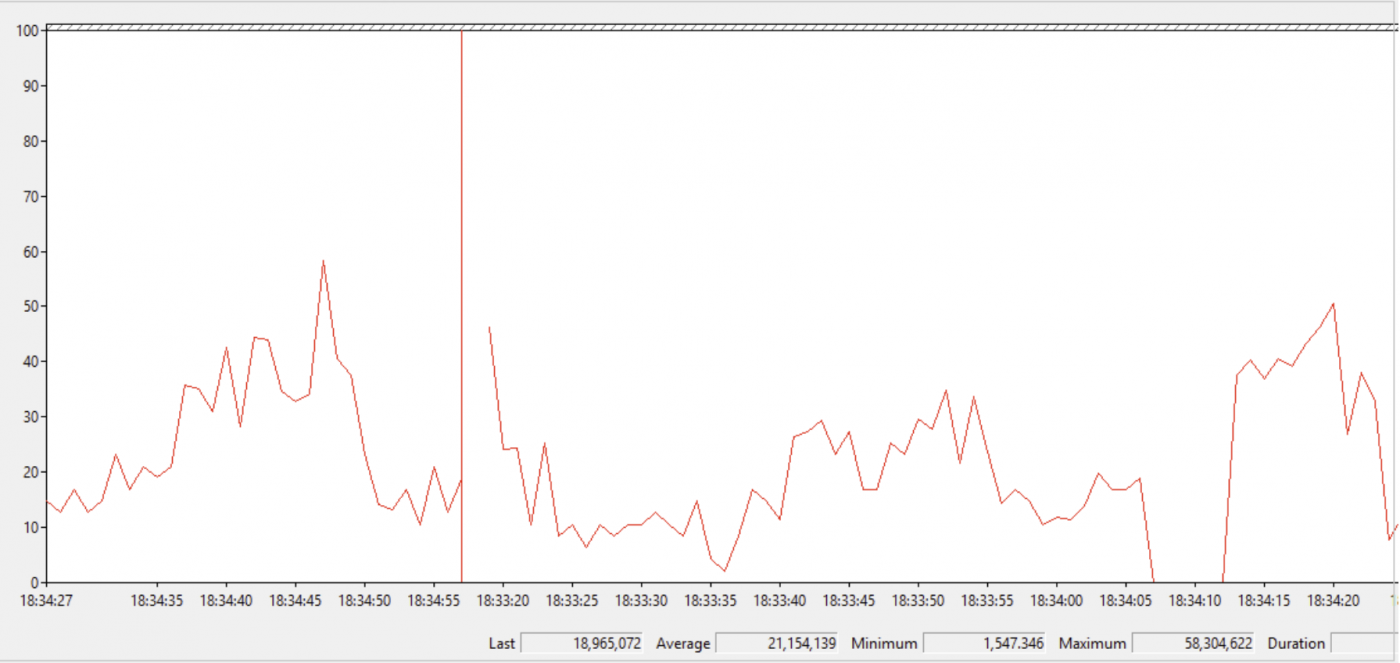
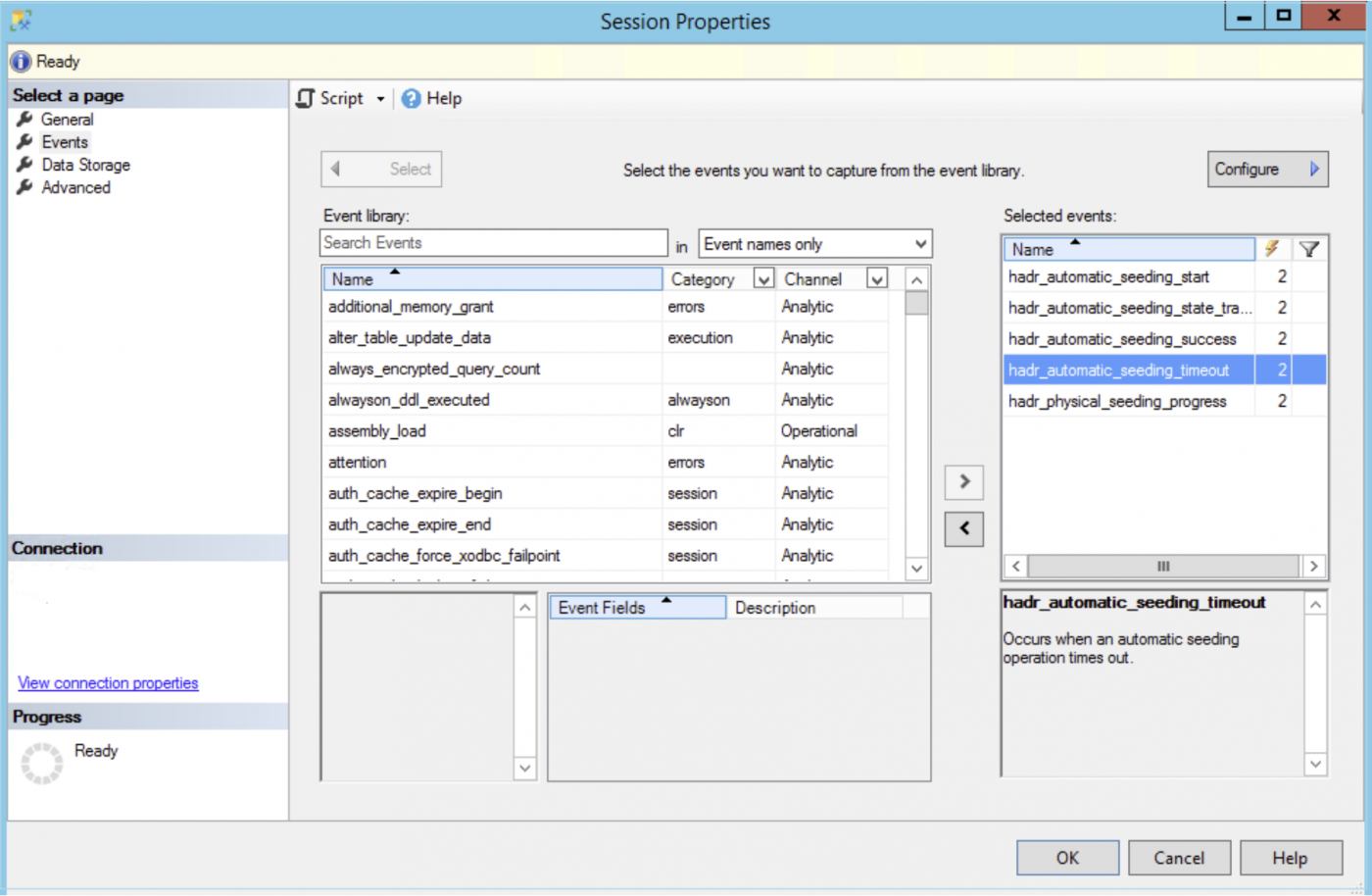
Wir können eine nützliche erweiterte Ereignissitzung konfigurieren, um den Fortschritt des automatischen Seedings in Always On Availability Groups mit den folgenden Ereignissen zu überwachen:
hadr_automatic_seeding_start: Erfasst den Start eines automatischen Seeding-Vorgangs.hadr_automatic_seeding_state_transition: Dieses Ereignis tritt ein, wenn ein automatischer Seeding-Vorgang seinen Zustand ändert.hadr_automatic_seeding_success: Tritt auf, wenn eine automatische Aussaat-Operation erfolgreich ist.hadr_automatic_seeding_timeout: Tritt auf, wenn eine automatische Seeding-Operation eine Zeitüberschreitung aufweist.hadr_physical_seeding_progress: Zeigt den Fortschritt des physischen Seedings an.
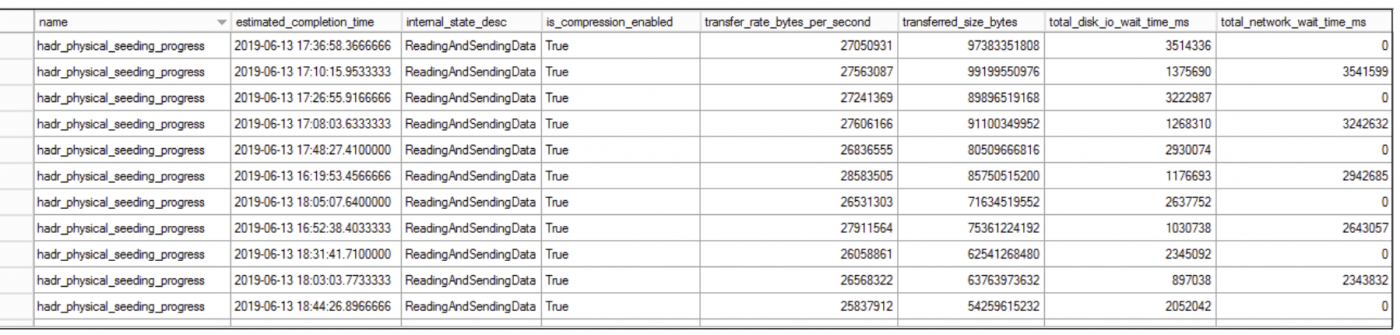
In der erweiterten Event Session erhalten Sie nützliche Informationen über den Fortschritt, die Übertragungsgröße, IO-Wartezeiten auf der Festplatte, Netzwerk-Wartezeiten usw. Sie können auch SQL-Protokolle verwenden, um den Fortschritt des automatischen Seedings zu überwachen.
Wichtige Punkte zum automatischen Seeding in Always-On-Verfügbarkeitsgruppen
- Sie können in SQL Server Always On auch andere Methoden zur anfänglichen Datensynchronisierung verwenden. Sie sollten entscheiden, welche Funktion für Ihre Umgebung am besten geeignet ist.
- Sie können das Transaktionsprotokoll während des automatischen Seedings nicht abschneiden. Dies könnte zu einem erheblichen Wachstum des Transaktionsprotokolls während des automatischen Seedings führen. Sie sollten diesen Faktor bei der Planung der Synchronisierung von Always On Availability Groups mit Automatic Seeding berücksichtigen.
- Der Datenbank- und Protokolldateipfad muss auf dem primären und allen sekundären Replikaten identisch sein.
- Wenn sich die sekundären Replikate an einem entfernten Standort mit begrenzter Netzwerkbandbreite befinden, sollten Sie diese Funktion nicht verwenden.
- Sie sollten auch die Datenbankgröße, die Last und das Wachstum des Transaktionsprotokolls auf der primären Replik berücksichtigen, wenn Sie diese Methode der anfänglichen Synchronisierung in Betracht ziehen.
Zusammenfassung
Das automatische Seeding bei der Initial Data Synchronization ist eine nützliche Funktion. Sie kann viel DBA-Zeit sparen, indem sie die Sicherung, das Kopieren und die Wiederherstellung von Datenbanken automatisch durchführt. Wir empfehlen Ihnen diese Funktion in Ihrer Always-On-Verfügbarkeitsgruppen-Umgebung auszuprobieren. Bei Fragen stehen wir Ihnen selbstverständlich als erfahrene SQL Server Spezialist:innen gerne im Rahmen einer kompetenten Beratung zur Verfügung. Wir freuen uns auf Ihre Kontaktaufnahme!
Unsere Expert:innen stehen Ihnen bei allen Fragen rund um Ihre IT Infrastruktur zur Seite.
Kontaktieren Sie uns gerne über das
Kontaktformular und vereinbaren ein unverbindliches
Beratungsgespräch mit unseren Berater:innen zur
Bedarfsevaluierung. Gemeinsam optimieren wir Ihre
Umgebung und steigern Ihre Performance!
Wir freuen uns auf Ihre Kontaktaufnahme!
55118 Mainz
info@madafa.de
+49 6131 3331612
Freitags:

