

Übersicht
Linux ist schon immer ein Thema in der IT, da das Open-Source Prinzip eine kostengünstigere Alternative zu Microsoft Produkten darstellt. Zudem hat Linux den Vorteil, dass es mit den Sicherheitsfunktionen weniger Angriffsfläche bietet als Windows und dabei genauso stabil, wenn nicht stabiler läuft. Darum ist es kein Wunder, dass auch bei Datenbanksystemen häufiger zu Linux Maschinen gegriffen wird. Aber es wird dabei immer auf eine einheitliche Systemstruktur geachtet. Doch wie sieht es nun aus, wenn man Maschinen mit verschiedenen Betriebssystemen hat? Anhand eines Beispiels wollen wir in diesem Artikel zeigen, wie man eine Availability Group (AG) aus Maschinen mit unterschiedlichen Systemen erstellen kann.
Voraussetzungen
Will man nun solch eine Availability Group erstellen, benötigt man sowohl eine Linux-, als auch eine Windows-Maschine. In unserem Beispiel haben wir Ubuntu 20.04 und Windows Server 2022 genutzt. Auf beiden Maschinen ist eine Instanz von SQL Server installiert. Zudem haben wir beide Maschinen unserer Domain hinzugefügt. Im Folgenden wollen wir die AG so erstellen, dass die Windows Maschine die primäre Instanz ist. Wir verwenden virtuelle Maschinen (VMs) und nennen die Linux VM linsql und die Windows VM winsql.
1. Schritt: Vorbereiten der Maschinen
Nachdem beide VMs aufgesetzt sind, müssen noch ein paar weitere Einstellungen vorgenommen werden. Zum einen muss das Always On Feature aktiviert und zum anderen sichergestellt werden, dass beide Maschinen miteinander kommunizieren können. Da dies für beide unterschiedlich ist, teilen wir diesen Punkt auf.
Windows
Beginnen wir mit der Aktivierung der Always On Funktion. Hierzu öffnen wir den Configuration Manager. Als nächstes müssen wir den SQL Server finden. Dafür navigieren wir auf der linken Seite zu dem Eintrag “SQL Server Services”. Auf der rechten Seite sollten die Services angezeigt werden, dabei auch der Server. Mit Rechtsklick öffnen wir die Eigenschaften und navigieren zum ‘Always On Availability Groups’ Reiter. Dort den Haken zum Aktivieren der Eigenschaft setzen. Damit die Änderungen übernommen werden, muss der SQL Server anschließend neu gestartet werden.
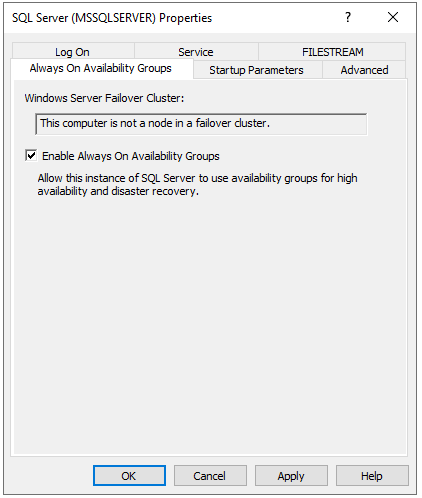
In der Zwischenzeit können wir uns um die Firewall kümmern. Wir wollen zwei Ports zulassen. Zum einen den Port, über den SQL Server kommuniziert. Dieser ist standardmäßig 1433. Den zweiten Port benötigen wir zur Endpoint Kommunikation beider Maschinen. Dafür wählen wir 5022. Wählen wir hier einen anderen, müssen wir später die Skripte anpassen. Sollten beide Maschinen nicht in derselben Domain sein, müssen wir zudem noch die ‘hosts’ Datei anpassen. Diese findet man unter C:\Windows\System32\drivers\etc. Hier einfach die IP und den Hostnamen der Linux Maschine angeben.
Linux
In Linux werden die Einstellungen des SQL Servers über die mssql-conf Datei verwaltet. Um hier die Always On Funktion zu aktivieren, kann folgender Befehl ausgeführt werden.
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
Auch hier muss der Server neu gestartet werden, damit die Einstellung übernommen wird. Dazu führen wir im Anschluss diesen Befehl aus.
sudo systemctl restart mssql-server.service
Desweiteren muss auch bei der Linux Maschine darauf geachtet werden, dass die richtigen Ports an der Firewall freigegeben sind und gegebenenfalls der Windows Hostname zusammen mit der IP angegeben wird. In Linux werden die Hostnamen in der Datei /etc/hosts gepflegt.
2. Schritt: SQL Server Verbindung herstellen
Für das Datenbank Mirroring soll die Kommunikation über Endpoints laufen. Deshalb müssen wir hierfür noch einige Dinge in SQL Server anlegen. Beginnen wollen wir mit Logins und Usern. Diese benötigen wir in beiden Instanzen. Hierfür können wir die folgenden SQL Befehle verwenden.
Da wir zur Authentifizierung Zertifikate brauchen, muss zuvor ein Master Key erstellt werden. Wenn das noch nicht geschehen ist, kann folgende Funktion benutzt werden.
Bis hierhin musste alles auf beiden Maschinen ausgeführt werden. Das ändert sich jetzt.
Auf der Windows Instanz erstellen wir nun ein Zertifikat, welches wir danach zur Authentifizierung auf der Linux Seite verwenden wollen. Dafür werden wir das Zertifikat nach dem Erstellen speichern.
Das gespeicherte Zertifikat müssen wir nun zusammen mit dem privaten Schlüsseln auf unsere Linux Maschine kopieren. Abgelegt haben wir die Dateien unter /var/opt/mssql/data, was der Standard Pfad für die SQL Daten ist. Am Ende müssen wir dem User Agent von SQL Server Rechte an den Dateien geben. Der User ist dabei standardmäßig ‘mssql’. Damit wir später auf keine Probleme stoßen, weisen wir sowohl den User, als auch die Gruppe als Owner der Dateien zu. Das geht unter Linux mit folgenden Befehlen.
sudo chown mssql:mssql /var/opt/mssql/data/dbCert.cer
sudo chown mssql:mssql /var/opt/mssql/data/dbCert.pvk
Wurde das Zertifikat erfolgreich übertragen, können wir damit auf der Linux Instanz ebenfalls ein Zertifikat erstellen. Wichtig ist dabei, dass das Passwort dasselbe ist, welches zum Verschlüsseln auf der Windows Instanz verwendet wurde.
Da wir nun auf beiden Instanzen ein Zertifikat haben, können wir die Endpoints erstellen. Über diese Endpoints wird die Kommunikation zwischen beiden Instanzen laufen. Darum muss folgendes Skript auf beiden Maschinen ausgeführt werden.
3. Schritt: Erstellen der Availability Group
Kommen wir zur tatsächlichen Magie. Denn nun können wir die Availability Group erstellen. Dafür wollen wir folgendes Skript auf der Windows Instanz ausführen, da diese zu Beginn die primäre Rolle haben soll. Davor kurz ein paar Worte zu den Angaben im Code.
- CLUSTER_TYPE: Da wir für die hier dargestellte Konfiguration keinen Cluster im Windows-Sinn erstellt haben, geben wir hier NONE an.
- ENDPOINT_URL: Hier geben wir die Daten unserer Endpunkte an. In unserem Beispiel nutzen wir TCP und den Port 5022.
- AVAILABILITY_MODE: Für den Anfang wollen wir diesen beim asynchronen Modus belassen.
- SEEDING_MODE: Da unsere SQL Instanzen auf verschiedenen Betriebssystemen laufen, sind auch die Pfade der Datenbanken unterschiedlich. Darum lassen wir diese Einstellung bei MANUAL.
- FAILOVER_MODE: Da wir kein Windwos Failover Cluster haben, wird hier nur der manuelle Failover Modus unterstützt.
- SECONDARY_ROLE: Es werden alle Verbindungen der sekundären Replikas zugelassen.
Sobald die Gruppe erstellt wurde, muss die Linux Instanz dieser auch beitreten. Dafür muss folgender Befehl auf der Linux Instanz ausgeführt werden.
Schon sind beide Instanzen in einer Availability Group. Öffnet man in SSMS das Dashboard zur Gruppe, sollten beide Maschinen angezeigt werden und eine erfolgreiche Verbindung bestehen. Jedoch wird es noch Warnungen geben. Das liegt daran, dass wir noch keine Datenbank in der Gruppe haben. Das wollen wir ändern.
Um eine Datenbank zu einer AG hinzufügen zu können, muss sich diese im Full Recovery Modus befinden und es muss ein vollständiges Backup existieren. Für unser Beispiel verwenden wir die AdventureWorks2022 Datenbank. Wir mussten den Recovery Modus ändern und haben im Anschluss ein Backup erstellt. Wenn Sie eine andere Datenbank verwenden wollen, prüfen Sie die Datenbank auf die Anforderungen. Das erstellte Backup wollen wir zur Linux Maschine kopieren, wo wir die Datenbank wiederherstellen. Wichtig ist hierbei, dass dies im NORECOVERY Modus geschieht. Zudem muss auf die richtige Pfadangabe geachtet werden. Für unser Beispiel, in dem sich die Datendateien und die TLog-Dateien im Verzeichnis /var/opt/mssql/data befinden, sieht das Skript so aus:
Wurde die Datenbank erfolgreich wiederhergestellt, fügen wir diese zur AG hinzu. Dazu wechseln wir wieder auf die primäre Instanz und führen folgenden Befehl aus.
Ob die DB erfolgreich hinzugefügt wurde, kann man entweder daran erkennen, dass hinter der Datenbank nun ein (Synchronized) steht. Alternativ öffnet man das Dashboard der Availability Group. In unserem Fall ist ein Fehler aufgetreten, bei dem die sekundäre Replika nicht synchronisiert war. Der Fehler bestand darin, dass wir noch keine sekundäre Replika der Datenbank hinzugefügt haben. Das lässt sich beheben, indem man ein Transaction Log Backup erstellt und dieses auf der sekundären DB wiederherstellt. Im Anschluss führt man diesen Befehl aus und die sekundäre Replika sollte den Status ‘Synchronizing’ haben.
Wechselt man nun noch den Commit Modus zu synchron, sollten beide Datenbanken ‘Synchronized’ sein.
Failover
Wie bereits erwähnt sind nur manuelle Failover mit dieser Availability Gruppe möglich. Diese kann man entweder über SSMS ausführen (Rechtsklick auf die Gruppe → ‘Failover…’), oder man macht dies ebenfalls über T-SQL Skripte. Auch wenn bei beiden Methoden vor einem Datenverlust gewarnt wird, sollte dies kein Problem sein, solange sich die Gruppe in einem synchronen Commit Modus befindet. Will man nun einen Failover machen, kann dazu folgender Befehl auf der sekundären Instanz ausgeführt werden.
Im Anschluss wechselt man auf die ehemals primäre Instanz und führt folgende Befehle aus.
Die ehemals primäre Instanz wechselt die Rolle zu Sekundär und fängt gleichzeitig an, die Datenbank zu synchronisieren.
Aber was ist nun, wenn die primäre Instanz ausfällt? Da es keinen automatischen Failover gibt, bleibt die DB so lange offline, bis ein Failover manuell erzwungen wird. Nehmen wir an, dass die primäre Instanz, in unserem Fall die Linux Maschine, ausfällt. Sobald wir dies bemerken, leiten wir manuell einen Failover von der Windows Maschine aus ein. Gleichzeitig entfernen wir die Linux Maschine (alte Primary) aus der Gruppe.
Die Linux Instanz wird entfernt, da Sie aufgrund der Fehlersituation, immer noch die primäre Rolle hat, sobald sie wieder online geht. Somit hätten wir zwei Availability Groups, die gleich sind, aber nicht miteinander kommunizieren. Darum nehmen wir die gedoppelte Gruppe offline, sobald die Linux Maschine wieder an ist. Diese Befehle führen wir auf der Linux Instanz aus.
Abhängig davon, wie lange die Maschine offline war, sind Änderungen an der originalen Datenbank vorgenommen worden. Will man nun die Transaction Logs auf die alte Datenbank übertragen, erhält man einen Fehler, dass die Log Nummern nicht übereinstimmen, bzw. es Logs mit anderen Nummern gibt. Darum löschen wir die DB auf der Linux Instanz.
Da die Linux Instanz aus der Gruppe entfernt wurde, wollen wir diese nun wieder hinzufügen. Darum führen wir folgenden Befehl auf der Windows Maschine aus.
Von der Linux Maschine aus, treten wir mit der lokalen Instanz wieder der AG bei. Dies machen wir, wie weiter oben schon, mit diesem Befehl.
Die Linux Instanz ist nun wieder ein Teil der AG und hat dabei die sekundäre Rolle. Jedoch besitzt sie noch keine sekundäre Replika der DB. Darum erstellen wir nun ein neues Full Backup der Datenbank und stellen dieses auf der sekundären Instanz mit NORECOVERY wieder her. Sobald das erfolgreich war, wollen wir noch ein Transaction Log Backup machen, welches wir ebenfalls auf die neue Instanz mit NORECOVERY spielen. Wenn das geschafft ist, fügen wir die sekundäre Replika der DB wieder der AG hinzu. Das geht mit folgendem Befehl.
Wenn es hierbei zu keinem Fehler kommt, sollte die Datenbank wieder synchron zu der originalen DB sein. Kontrollieren kann man das über das Dashboard.
Fazit
Auch wenn eine solche Gruppe leider ein paar Funktionen einer reinen Windows AG fehlen, stellt dies dennoch eine interessante Alternative dar eine AG zu aufzusetzen. Wir hoffen, wir konnten mit diesem Artikel verständlich erklären, wie man eine Availability Group auch mit verschiedenen Betriebssystemen erstellt und wie man ein Failover auch bei Ausfall durchführen kann. Sollten Fragen aufkommen, stehen unsere Experten für Sie bereit. Gerne können Sie einen unverbindlichen Termin über unser Kontaktformular ausmachen.




