

Einleitung
In diesem Artikel gehen wir verstärkt auf den Prozess des Oracle Upgrades von 12c auf 19c mithilfe des Transient Logical Upgrades ein und erklären Ihnen wie Sie das Upgrade mit minimalsten Ausfallzeiten erfolgreich durchführen können.
Transient Logical Upgrade
Mit Database 11g Release 1 hat Oracle eine Möglichkeit eingeführt, mit der physische Standby-Datenbanken mit DataGuard verwendet werden können, um rollende Datenbank-Upgrades nahezu ohne Ausfallzeiten auszuführen. Hierzu muss man die physische Standby-DB in eine logische Standby-DB konvertieren. Die Vorgehensweise, eine Datenbank mit Hilfe einer logischen Standby Datenbank zu aktualisieren wird auch als “Transient Logical Standby - Rolling Upgrade” bezeichnet.
Diese Upgrade-Methode ist aus mehreren Gründen attraktiv:
- Sie ermöglicht es, vorhandene physische Standby-Datenbanken für rollende Datenbank-Upgrades zu verwenden
- Es wird kein zusätzlicher Speicherplatz benötigt, um eine separate logische Standby-Datenbank nur für den Zweck eines Rolling Upgrades bereitzustellen
- Der vorübergehende logische Rolling-Upgrade-Prozess erfordert nur die Ausführung eines einzelnen Katalog-Upgrades, um beide Primär- und Standby-Datenbanken auf eine neue Oracle-Version zu heben. Das Upgrade des Katalogs der zweiten Datenbank erfolgt implizit und für den Administrator transparent.
- Wenn der Upgrade-Vorgang abgeschlossen ist, wird die Konfiguration auf die ursprüngliche Konfiguration einer primären Datenbank mit einer physischen Standby-Datenbank zurückgesetzt.
Lizenzbetrachtungen
Im Oracle License Guide befinden sich Einträge zu den Themen
- Rolling Upgrades mit Active DataGuard
- Rolling Upgrades—Patch Set, Database, and Operating System
Die Spaltenwerte N und Y geben hier lediglich an, ob das entsprechende Feature in der betreffenden Umgebung verfügbar ist. Lizenzspezifische Informationen befinden sich hier in der Spalte Notes. Demnach erfordern Rolling Updates unter Verwendung von Active DataGuard eine zusätzliche Lizenzierung.

Das hier eingesetzte physru_v3 Skript verwendet Active DataGuard nicht. Dementsprechend erfordert die Verwendung dieses Skripts keine zusätzliche Lizenzierung.
Die Lizenzierung im Oracle Umfeld ist oft sehr komplex und ändert sich von Zeit zu Zeit. Bitte konsultieren Sie daher immer den aktuellsten Oracle License Guide oder wenden Sie sich bei Fragen an unsere Oracle Spezialisten!
Ausgangslage
Wir haben als Ausgangspunkt eine 12.2.0.1 Container Datenbank mit DataGuard Konfiguration (Primary: ODB01P, Physical Standby: ODB01PR) und möchten diese mit geringstem Ausfall auf die Zielversion 19.17.0.0.221018 aktualisieren. Die neue Softwareversion wurde im Vorfeld auf beiden Hosts in neuen Homeverzeichnissen installiert.
Vorbereitungen und Konfiguration
Die diversen Checks und Konfigurationsschritte wurden von Oracle in einem Shell Skript zusammengestellt, welches viele der erforderlichen Aufgaben automatisiert. Dies macht die Ausführung des Prozesses einfacher und zuverlässiger.
Das Script liegt in der Version 3 vor und kann unter dem Namen physru_v3.sh über das Dokument 949322.1 heruntergeladen werden.
physru_v3.sh:
Das Shell Skript mit dem Namen physru_v3.sh führt ein Upgrade für die Oracle RDBMS-Versionen 11gR1 und höher in einer DataGuard Umgebung aus, wobei die physische Standby Datenbank temporär als logische Standby Datenbank betrieben wird. Ein solches Upgrade umfasst normalerweise zahlreiche SQL-Operationen und -Validierungen. Das Physru-Skript reduziert die Anzahl der Schritte erheblich und lässt dem Benutzer die folgenden verbleibenden Schritte:
Aufrufen von DBUA oder catupgrd.sql, um die (logische!) Standby-Datenbank zu aktualisieren.
- Starten der aktualisierten Standby-Datenbank im neuen Oracle-Home.
- Starten der ehemaligen Primärdatenbank im neuen Oracle-Home.
- Starten und Stoppen von RAC-Instanzen.
- Deaktivieren und Aktivieren von RAC.
Das Physru-Skript muss konstruktionsbedingt insgesamt dreimal aufgerufen werden, um das rollende Upgrade abzuschließen.
Wenn das Skript einen Punkt erreicht, an dem ein Eingriff erforderlich ist, benachrichtigt es den Benutzer darüber, welcher der oben genannten Schritte auszuführen ist. Nach Abschluss des jeweiligen Benutzervorgangs muss der Benutzer das Skript erneut aufrufen, um das fortlaufende Upgrade fortzusetzen. Hierbei ist jeweils die exakt gleiche Parametrisierung erforderlich. Das Skript “merkt” sich jeweils, in welchem Schritt es sich befindet.
Sollte ein Fehler auftreten, gibt das Skript einen Fehlerkontext aus, um die Fehlerbehebung bei der Unterbrechung des parallelen Upgrades zu unterstützen.
Nachdem alle Probleme behoben wurden, kann das Skript erneut aufgerufen werden, um an der Stelle der Unterbrechung fortzusetzen.
Physru unterstützt sowohl RAC- als auch Single-Instance-Datenbanken in beliebiger Kombination.
Da Logical Standby Datenbanken auf den Fähigkeiten des LogMiners beruhen, werden bestimmte Datentypen nicht unterstützt. Oracle stellt hier eine spezielle View mit dem Namen DBA_LOGSTDBY_UNSUPPORTED bereit. Die View zeigt Schemas, Tabellen und Tabellenspalten an, die nicht unterstützte Datentypen enthalten.
Fragen wir die Objekte ab, die Probleme bereiten:
Wenn die Primärdatenbank nicht kompatible Objekte enthält, schließt der Log Apply Dienst diese Objekte automatisch aus, während die übrigen Redo-Operationen auf der logischen Standby-Datenbank angewandt werden.
Eine logische Standby-Datenbank kann keine Aktualisierungen für die folgenden Objekte akzeptieren:
- Tabellen oder Sequenzen die SYS gehören
- Tabellen die Tabellenkomprimierung verwenden
- Tabellen die einer Materialized View zugrunde liegen
- Globale temporäre Tabellen (GTTs)
Darüber hinaus können Tabellen, die die folgenden nicht unterstützten Datentypen verwenden, nicht mit dem hier beschriebenen Verfahren aktualisiert werden:
- Datentypen
BFILE,ROWIDundUROWID - Benutzerdefinierte Typen
- Multimedia-Datentypen wie Oracle Spatial, ORDDICOM und Oracle Text
- Sammlungen (z. B. verschachtelte Tabellen,
VARRAYs) - SecureFile-LOBs
OBJECT RELATIONAL XMLTypenBINARY XMLs
Wenn unsere Datenbank solche Objekte enthält, muss man die Objekte prüfen. Sind keine Änderungen möglich, muss gegebenenfalls eine andere Upgrade-Methode ausgewählt werden.
Prüfen wir das Redo Apply:
Die Standby-Datenbank muss entweder im Maximum Availability oder im Maximum Protection Modus sein. Unsere Konfiguration war in Maximum Performance, sodass auf Maximum Availability umgeschaltet wird.
DataGuard
Mit DataGuard ist es möglich, sämtliche Datenänderungen an eine räumlich getrennte Datenbank zu senden. Diese kann dann geplant (Switchover) oder bei einem Ausfall der Primärdatenbank (Failover) den Betrieb übernehmen.
Eine DataGuard-Konfiguration läuft immer in einem von drei Datenschutz-Modi (auch Redo-Transportregeln genannt). Alle drei Modi bieten ein hohes Maß an Datenschutz - unterscheiden sich jedoch in Bezug auf die Auswirkungen, die jeder auf die Verfügbarkeit und Leistung der primären Datenbank hat.
Maximum Protection
Dieser Schutzmodus garantiert, dass kein Datenverlust auftritt, wenn die primäre Datenbank ausfällt. Um dieses Schutzniveau bereitzustellen, müssen die Redo-Daten, die zur Wiederherstellung jeder Transaktion benötigt werden, sowohl in das lokale Online-Redo-Log als auch in ein Standby-Redo-Log in mindestens einer Standby-Datenbank geschrieben worden sein, bevor die Transaktion festgeschrieben wird. Um sicherzustellen, dass kein Datenverlust auftritt, wird die primäre Datenbank heruntergefahren, wenn ein Fehler sie daran hindert, ihren Redo-Stream in mindestens eine synchronisierte Standby-Datenbank zu schreiben.
Maximum Availability
Dieser Schutzmodus bietet den höchstmöglichen Datenschutz, ohne die Verfügbarkeit der primären Datenbank zu beeinträchtigen. Wie im Maximum Protection Modus werden Transaktionen erst festgeschrieben, wenn alle für die Wiederherstellung dieser Transaktionen erforderlichen Redo-Daten in das Online-Redo-Log und in mindestens eine synchronisierte Standby-Datenbank geschrieben wurden. Im Gegensatz zum Maximum Protection Modus wird die primäre Datenbank nicht heruntergefahren, wenn ein Fehler sie daran hindert, ihren Redo-Stream in eine synchronisierte Standby-Datenbank zu schreiben. Stattdessen arbeitet die primäre Datenbank in RESYNCHRONIZATION, bis der Fehler behoben ist und alle Protokolllücken behoben wurden. Sobald dies der Fall ist, nimmt die primäre Datenbank automatisch den Betrieb im Modus mit maximaler Verfügbarkeit wieder auf.
Maximum Performance
Dieser Schutzmodus bietet den höchstmöglichen Datenschutz, ohne die Leistung der primären Datenbank zu beeinträchtigen. Dies wird erreicht, indem zugelassen wird, dass eine Transaktion festgeschrieben wird, sobald die Redo-Daten, die zum Wiederherstellen dieser Transaktion erforderlich sind, in das lokale Redo-Protokoll geschrieben werden. Der Redo-Datenstrom der primären Datenbank wird auch in mindestens eine Standby-Datenbank geschrieben, aber dieser Redo-Stream wird asynchron in Bezug auf die Festschreibung der Transaktionen geschrieben, die die Redo-Daten erstellen.
Wenn Netzwerkverbindungen mit ausreichender Bandbreite und Latenz verwendet werden, bietet dieser Modus ein Datenschutzniveau, das sich dem des Modus mit maximaler Verfügbarkeit annähert, mit minimalen Auswirkungen auf die Leistung der primären Datenbank.
Um Maximum Availability einzuschalten, muss auf beiden Datenbanken der DataGuard Parameter Logxptmode auf SYNC eingestellt werden.
LogXptMode
Der Redo-Log-Transport von Oracle DataGuard bietet synchronen und asynchronen Log-Transportmodus. Der Unterschied besteht darin, wann das COMMIT stattfindet.
- LogXptMode = (‘
SYNC‘): Wie der Name schon sagt, synchronisiert derSYNC-Modus die primäre mit der Standby-Datenbank und alle DML auf dem primären Server werden NICHT festgeschrieben, bis die Protokolle erfolgreich zu den Standby-Servern transportiert wurden. Der synchrone Protokolltransportmodus ist für die Datenschutzmodi Maximum Protection und Maximum Availability erforderlich. - LogXptMode = (‘
ASYNC‘): Umgekehrt ermöglicht der asynchrone Modus (ASYNC), dass Updates (DML) auf dem primären Server festgeschrieben werden, bevor die Protokolldatei auf den Standby-Servern ankommt. Der asynchrone Protokolltransportmodus ist für den Datenschutzmodus Maximum Performance erforderlich.
Schließlich Konfiguration auf Maximum Availability umschalten
Danach prüfen wir den Status der Standby-DB:
Flashback muss auf beiden Seiten (Primary und Standby) eingeschaltet sein:
Standby File Management soll auf beiden Seiten (Primary und Standby) auf auto gestellt sein:
Der DataGuard Broker muss während der Verwendung des physru-Skripts beendet werden.
Natürlich soll die Primary Datenbank geöffnet und im Read-Write Modus stehen:
Die Standby-DB bleibt im Mount-Status:
Ausführung
Schritt 1 - Erste Physru Skript Ausführung
Nachdem wir die nötigen Checks durchgeführt haben, können wir das physru_v3.sh Skript zum ersten mal starten.
Was macht das Skript?
Im ersten Aufruf führt das Skript folgende Aktionen durch:
- Stage 0 - Prechecks
- Stage 1 - Erstellen eines Backups und eines Restore Punkts
- Stage 2 - Konvertierung des physischen Standby-DB in eine logische
Das Skript braucht folgende Parameter zum starten:
username= hier sollte der User sys verwendet werdenprimary_tns= tns-Dienstname der primären Datenbankstandby_tns= tns-Dienstname der Standby-DBprimary_name= db_unique_name primären Datenbankstandby_name= db_unique_name der Standby-DBupgrade_version= Version der Ziel-Instanz
Wenn unsere Pluggable Datenbank auf der Standby Seite nicht automatisch startet - weil in der physischen Standby DB der Mount Status für die PDB gespeichert wurde - werden wir am ende bei 99% stecken bleiben und nach 30 Minuten einen Timeout erhalten.
Das ist aber kein Problem, dafür starten wir die Pluggable-DB auf der Standby Seite:
Wir müssen das Timeout nicht abwarten, sondern können das Skript vorzeitig beenden und erneut starten. Es wird merken, dass der letzte Lauf entweder fehlgeschlagen ist oder der Benutzer es abgebrochen hat und fragt nach, wie wir weiter vorgehen möchten. Hierbei stehen die folgenden Möglichkeiten zur Verfügung:
- Fortsetzen des Upgrade von dort, wo die letzte Ausführung aufgehört hat
- Von vorne starten
- Skript beenden
Wir wählen 1 und das Skript macht weiter wo es zuletzt aufgehört hat:
Wir können nun schauen was das Skript mit unserer physischen Standby-DB angestellt hat:
Die physische wurde in eine logische Standby-DB umgewandelt und wie das Skript schon ausgegeben hat, ist die Standby-DB bereit für das Upgrade. Währenddessen läuft unsere Primary Instanz aktiv weiter.
Schritt 2 - Upgrade der logischen Standby-DB
Das Upgrade kann manuell oder mittels dbua erfolgen. Wir werden dbua benutzen.
Wählen wir unsere Datenbank aus und verwenden wir User und Passwort des SYS Users:
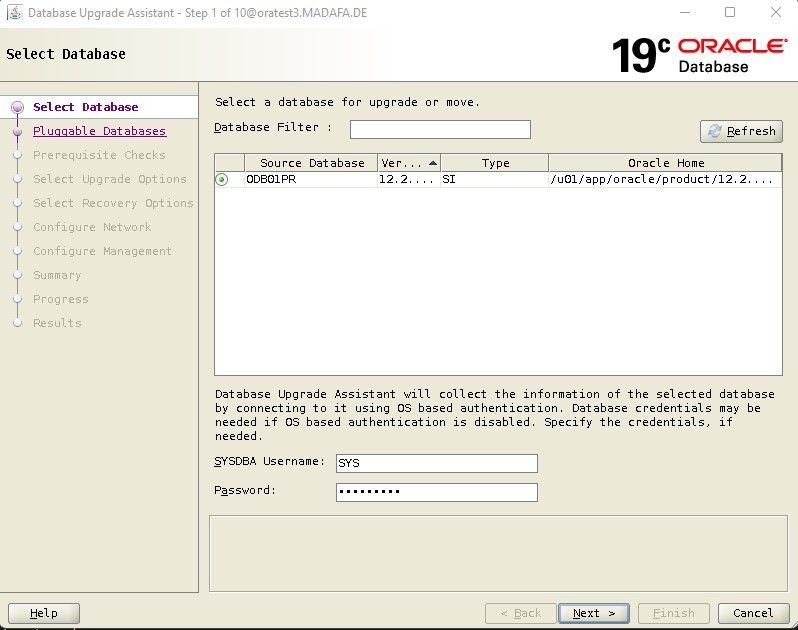
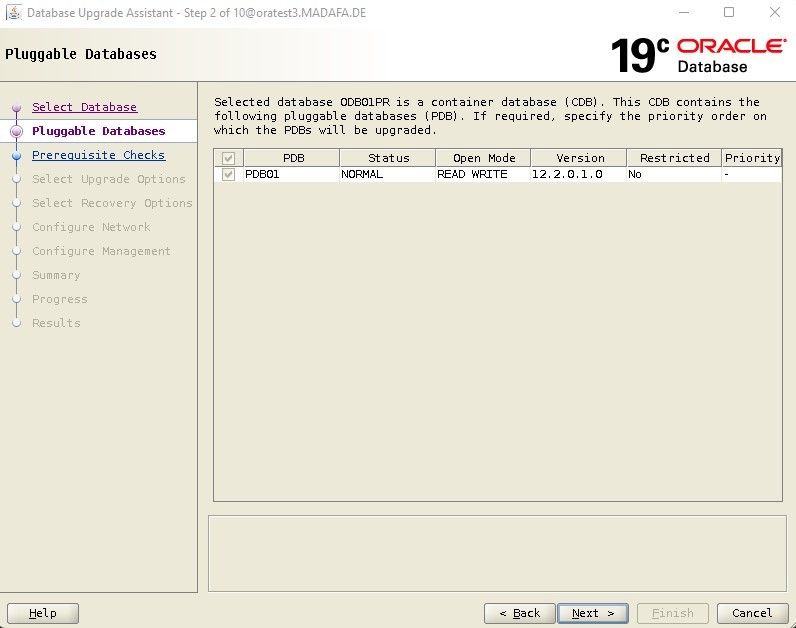
Im zweiten Schritt wählen wir die PDB aus
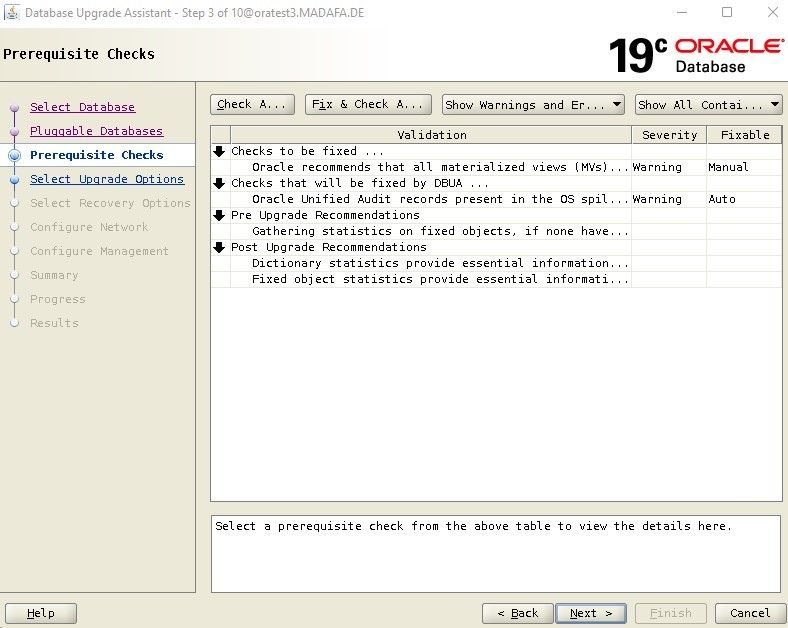
Der Upgrade Assistent führt nun die PreUpgrade Checks durch. Wir prüfen und beheben die Fehlermeldungen die mit manual gekennzeichnet sind. Danach können wir mit Fix & Check Again die Checks erneut durchführen und mit Next weiter gehen.
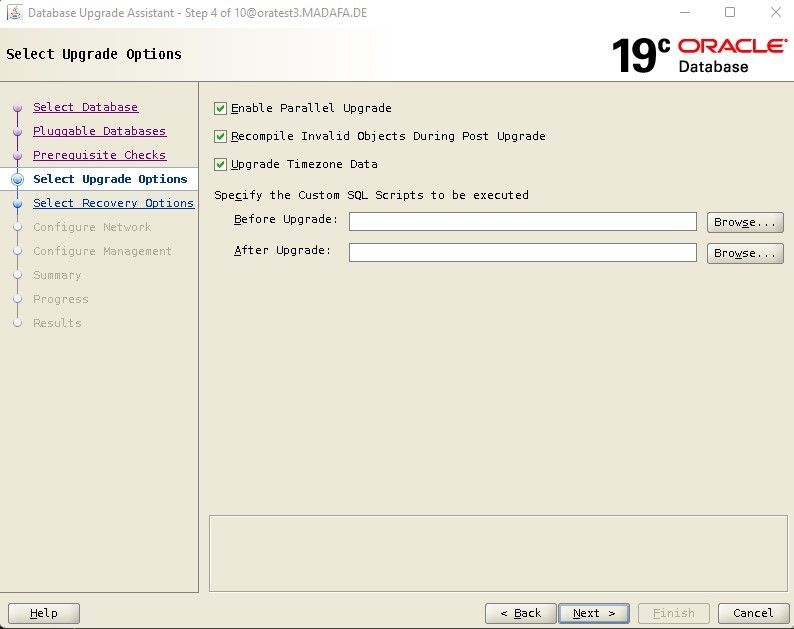
Bei den Upgrade Optionen können die Standard Werte bleiben und wir fahren mit Next fort.
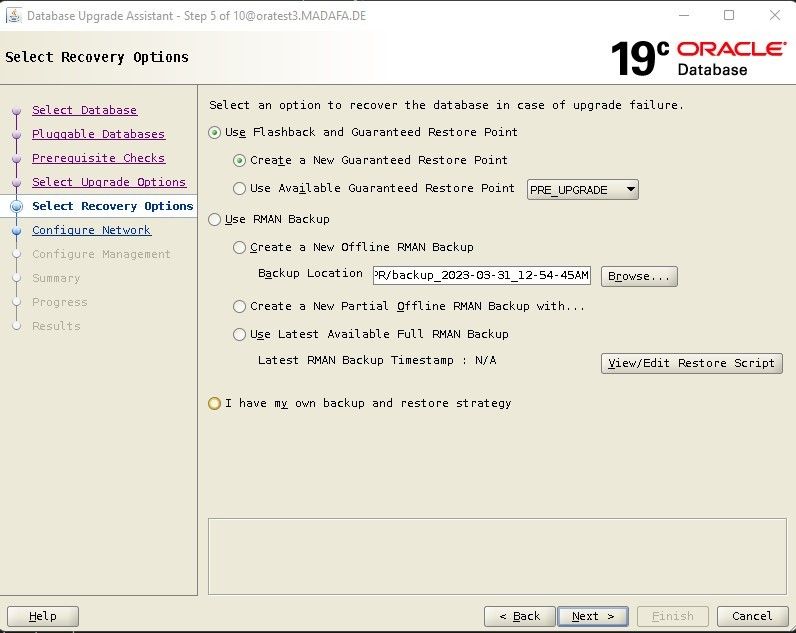
In Schritt 5 können wir die Recovery Optionen einstellen, wobei wir zwischen Flashback, vom Upgrade durchzuführendes RMAN-Backup oder einem bereits zuvor erstellten Backup auswählen können. Im Fall von Flashback kann ein bereits existierender oder ein neuer Restore-Point spezifiziert werden.
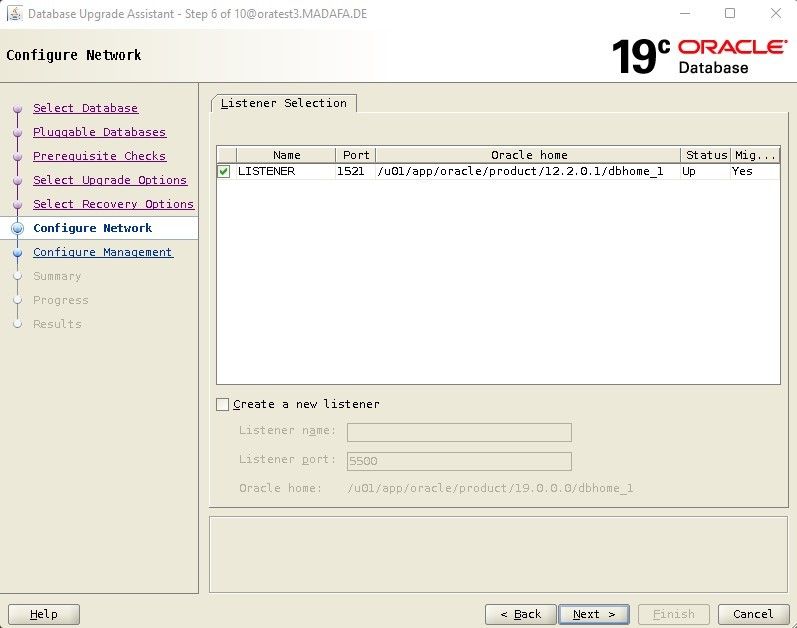
Auf Einzelinstanzsystemen kann man entweder einen vorhandenen Listener auswählen oder einen neuen Listener erstellen. Wenn ein neuer Listener erstellt werden soll, muss man den Listener-Namen und eine Portnummer für den Listener angeben. In diesem Fall müsste die Tnsnames Datei aber auf beiden Seiten entsprechend geändert werden. Wählen wir den Listener aus und drücken auf Next.
Wir konfigurieren bei Bedarf OEM später separat, deshalb lassen wir das OEM Setup hier aus.
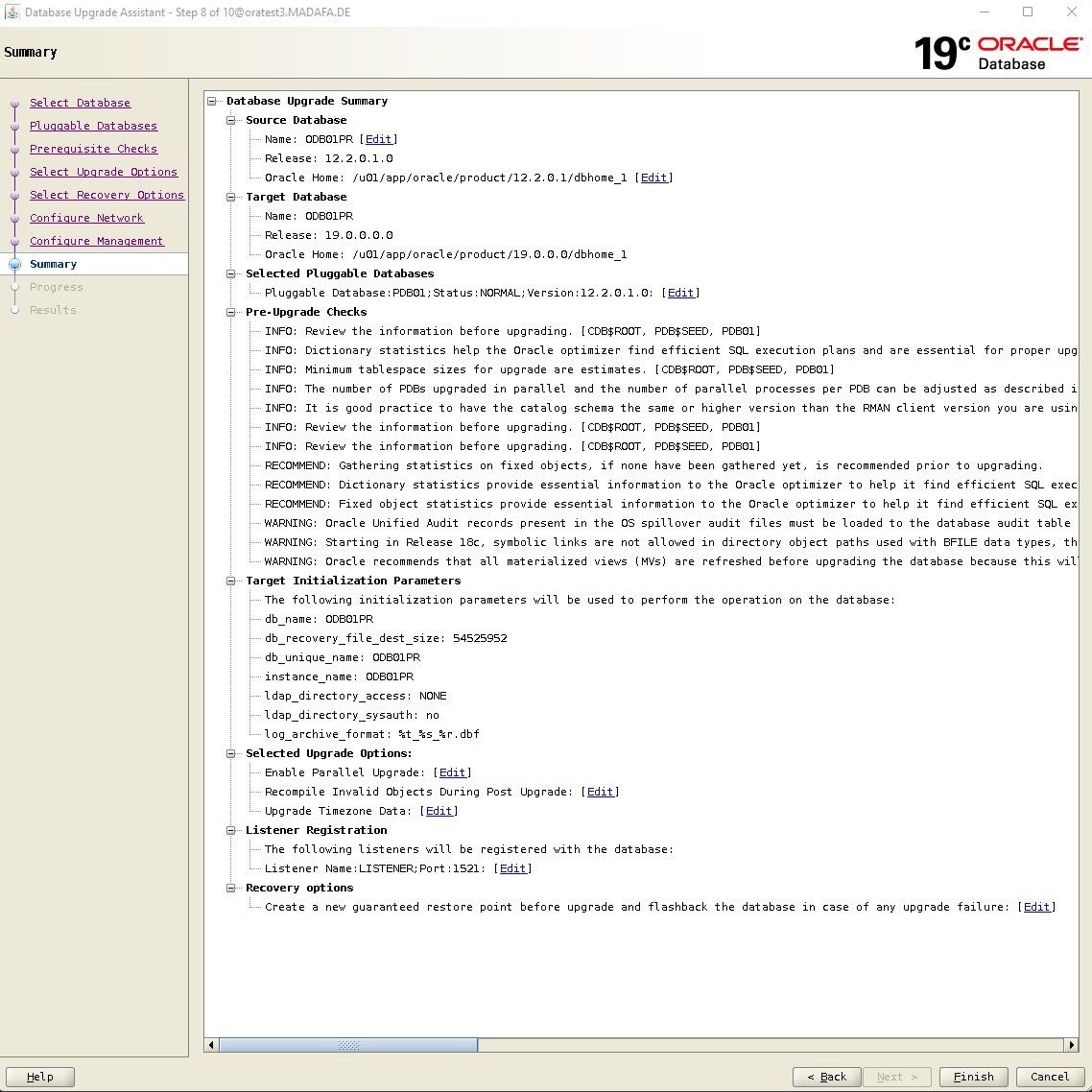
Im nächsten schritt des Upgrade Assistenten erhalten wir die Zusammenfassung:
Danach startet das Upgrade mit dem Finish Button und es wird eine Seite angezeigt, auf der die Upgrade-Aktivitäten bzw. deren Status angezeigt werden.
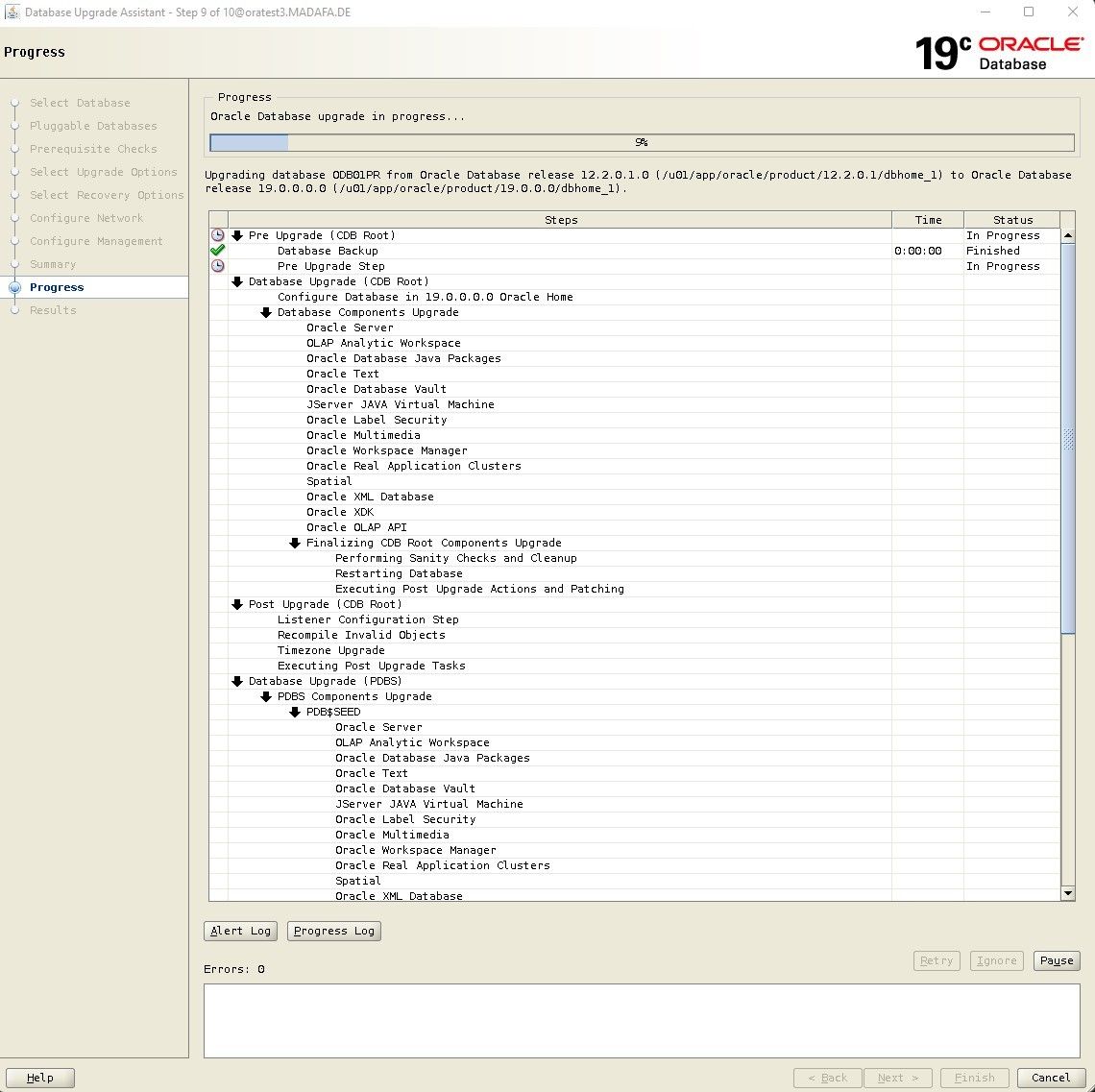
Abschließend erhalten wir die Ergebnisse des Upgrades:
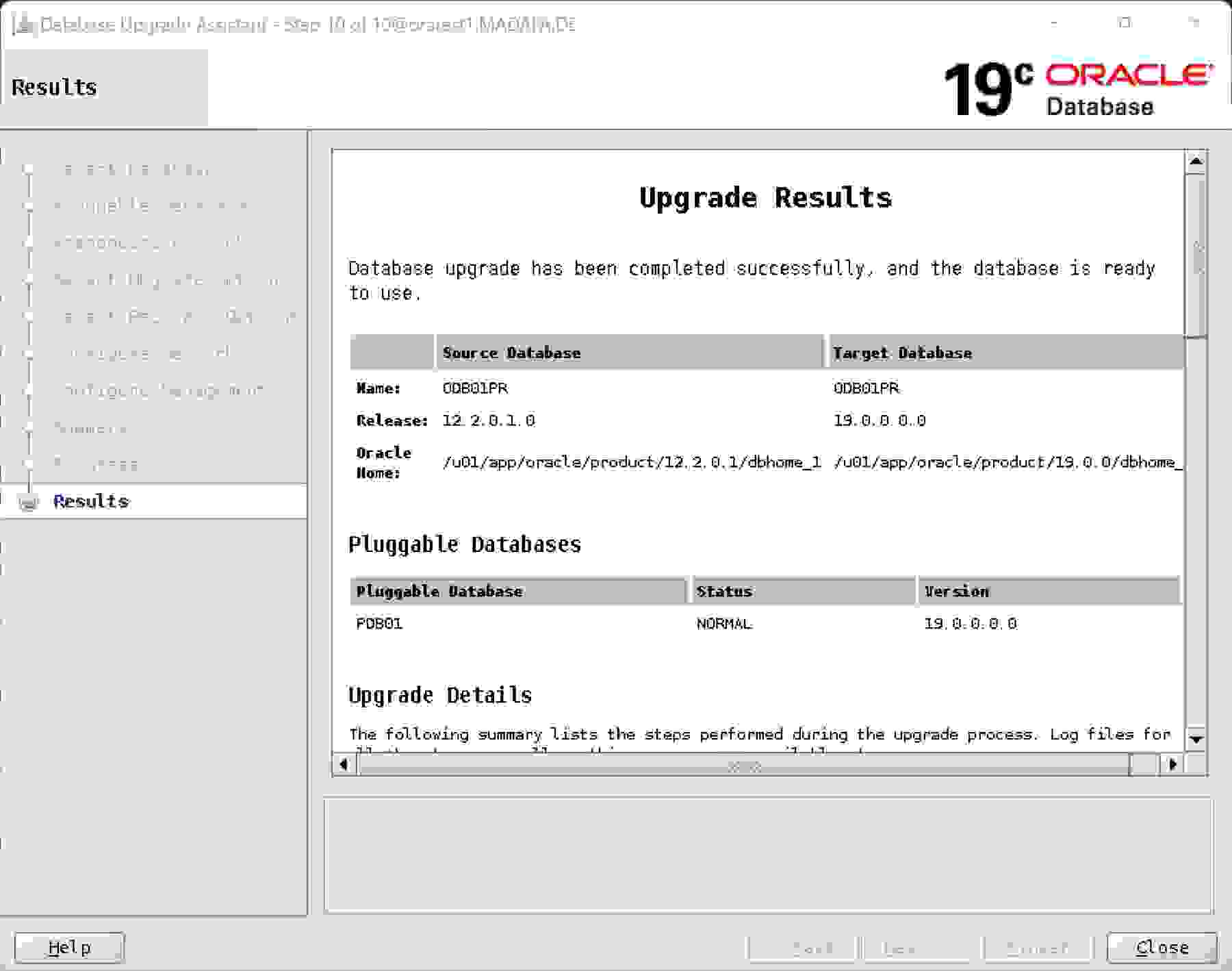
Das gesamte Upgrade hat ca. eine Stunde gedauert. In den Resultaten kann man sich die Dauer der jeweiligen Schritte ansehen.

Das gesamte Upgrade hat ca. eine Stunde gedauert. Damit ist unsere Standby-DB auf 19c aktualisiert.
Schritt 3 - Physru Skript zweiter Lauf
Nachdem unsere Standby-DB auf die Zielversion aktualisiert wurde, können wir das physru Skript zum 2 mal starten. Das Skript führt einen Switchover durch. Hierbei werden wir für die Dauer des Umschaltvorgangs eine kleine Unterbrechung haben, aber die meisten Applikationen merken das nicht einmal.
Was macht das Skript?
Im zweiten Aufruf macht das Skript folgendes:
- Stage 0 - Prechecks
- Stage 3 - Validiert und prüft die logische Standby-DB mit der neuen Version
- Stage 4 - Switchover auf die logische Standby-DB. Damit wird diese zur neuen Primary
- Stage 5 - Die alte Primary-DB wird auf den PreUpgrade Restore Punkt zurückgestellt und in eine physische Standby-DB konvertiert. Damit befinden sich die Daten der ehemaligen Primärdatenbank jetzt wieder im gleichen Status, wie zum Zeitpunkt des ersten physru-Aufrufs. Die während des Upgrades erfolgten Datenänderungen befinden sich in der ehemaligen Standby-DB.
Das Skript weist darauf hin, dass die alte Primary-DB abeschaltet wurde und wir können sie nun im neuen Homeverzeichnis starten. Dazu müssen wir zuvor die Passwort-Datei und das Spfile der alten Version in das neue Homeverzeichnis kopieren.
Fragen wir den Status ab:
Schritt 4 - Physru Skript dritter Lauf
Beim dritten Aufruf des Skripts werden die Änderungen der neuen Primary-DB in die neue Standby-DB geschrieben. Abschließend fragt das Skript nach, ob die Rollen der DB wieder ausgetauscht werden sollen, sodass die ursprüngliche Primary-DB und Standby-DB wieder als Primary-DB bzw. Standby-DB betrieben werden. Es ist nicht zwingend erforderlich, einen weiteren Switchover durchzuführen, wenn man die Ausfallzeiten auf einem absoluten Minimum halten möchte.
Wenn man mit N antwortet, bleibt ODB01P die physische Standby-DB und ODB01PR die Primary-DB.
Zu Demonstrationszwecken antworten wir jedoch mit yes (y), sodass wir den Originalzustand, das heißt die Primary-DB auf dem Primary Host und die Standby-DB auf der Standby-Seite haben. Unabhängig von unserer Antwort laufen jetzt aber beide Instanzen in der neuen 19c Umgebung.
Was macht das Skript?
Im dritten Aufruf macht das Skript folgendes:
- Stage 0 - Prechecks
- Stage 6 - Ausführung des Media Recovery ab dem anfangs gesetzten Restore-Point. Hierbei erhält die neue Standby-DB die Katalog-Updates und die während des Updates durchgeführten Benutzertransaktionen aus der neuen Primary-DB
- Stage 7 - Switchback (optional)
Fazit
Wir haben ein Upgrade durchgeführt und das laut Skriptausgaben mit lediglich 15 Sekunden Ausfallzeit für den Switchover und 30 Sekunden Ausfallzeit für den Switchback, was mit herkömmlichen Upgrade Methoden nicht erreichbar ist. Das hier dargestellte Verfahren des Transient Logical Upgrade hat jedoch auch seine Nachteile, welche wir am Anfang des Artikels erwähnt haben.
Welchen Upgrade-Weg wir nehmen, hängt von unserer Konfiguration ab. In jedem Fall sollte dieses Verfahren im Vorfeld ausgiebig mit einer Konfiguration getestet werden, die der Produktivumgebung möglichst ähnlich ist. Wir empfehlen hier den Aufbau einer Testumgebung mit einer exakten Kopie der Produktion.
Gerne stehen Ihnen rund um das Thema Oracle und dazugehörige Upgrades unsere Experten zur Seite und helfen Ihnen gerne mit Best Practices und Optimierungslösungen weiter. Kontaktieren Sie uns dafür gerne unverbindlich über unser Kontaktformular. Wir freuen uns von Ihnen zu hören.




