

Da Docker Container unveränderlich und vergänglich sind, geben sie uns die Möglichkeit, im Falle einer Konfigurationsänderung oder eines Upgrades der Containerversion, einen neuen Container bereit zu stellen und den veralteten zu verwerfen, anstatt diesen neu zu konfigurieren. Dieses Konzept einer unveränderlichen Infrastruktur, in welcher Dinge nicht mehr geändert werden, sobald sie ausgeführt werden, bringt enorme Vorteile im Bezug auf Zuverlässigkeit und Konsistenz sowie die Reproduzierbarkeit von Änderungen.
Doch diese Vorteile kommen nicht ohne einen Kompromiss: Docker Container sind persistent. Das bedeutet, dass Änderungen und Konfigurationen eines Containers im Falle eines Neustarts des Hosts oder des Containers, erhalten bleiben. Nach dem tatsächlichen Löschen eines Containers gehen diese Änderungen aber verloren gehen. Doch was ist, wenn eine Anwendung innerhalb eines Containers einzigartige Daten erzeugt, wie beispielsweise Datenbanken oder einen Schlüsselwertspeicher? Wie können wir diese essentiellen Daten im Falle einer Aktualisierung und dem Bereitstellen eines neuen Containers behalten, wenn wir doch den alten löschen?
Hierfür bietet Docker zwei Lösungen: Data Volumes und Bindmounts. In diesem Beitrag wollen wir uns die Verwendung von Data Volumes genauer anschauen und an einem praktischen Beispiel verdeutlichen.
Die Verwendung eines Data-Volumes
Ein Data-Volume eines Containers bietet die Möglichkeit, Daten, die innerhalb eines Containers ‘leben’, einsehen und weiterhin verwenden zu können, auch wenn sie bereits gelöscht wurden. Hierfür wird ein ein Pfad innerhalb des Containers konfiguriert, der auf einen tatsächlichen Pfad auf dem Host zeigt, in dem die Daten dauerhaft gespeichert sind. Um besser zu verstehen wie das funktioniert schauen wir uns in den folgenden Abschnitten einen Container mit einem konfigurierten Data Volume an.
Data Volumes werden für einen Docker Container in dem zugehörigen Dockerfile mithilfe des Schlüsselworts “VOLUME” konfiguriert. Zur Veranschaulichung betrachten wir einmal das Dockerfile des offiziellen msql Docker-Images. Dieses ist auf der Internet Seite Docker Hub unter https://hub.docker.com/_/mysql frei einsehbar.
Wir betrachten nun einen Auszug des Dockerfiles und finden in der Tat das konfigurierte Volume:

Diese Konfiguration gibt dem Container beim Start die Anweisung, einen tatsächlichen Volume-Speicherort zu erstellen und dieses dem Verzeichnis /var/lib/mysql innerhalb des Containers zuzuweisen. Dies hat zur Folge, dass alle Daten, die innerhalb des Containers abgelegt sind, die Lebenszeit des Containers überdauern und auch noch nach dem Entfernen des Containers erhalten bleiben. Nur durch manuelles Löschen des Volumes können die Daten entfernt werden.
Schauen wir uns nun einmal das Image selbst an. Hierfür laden wir uns das Image mit dem Befehl
herunter. Nach dem Download können wir uns mit dem Befehl
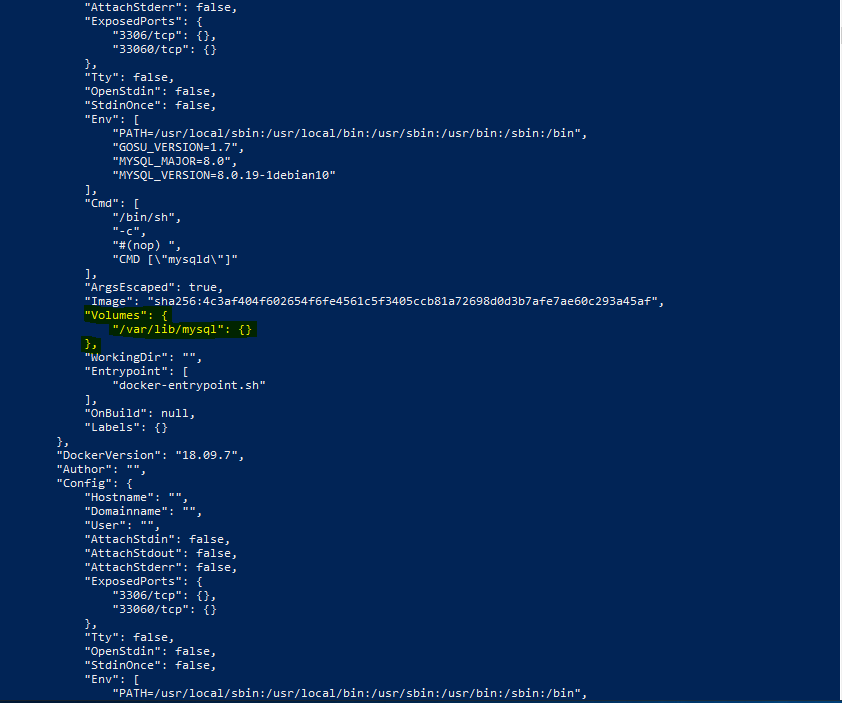
die genaue Konfiguration des Images ansehen. Und auch hier können wir das im Dockerfile konfigurierte Volume finden:
Mit dem Befehl
erstellen wir nun einen Container, basierend auf dem zuvor heruntergeladenen mysql Image. Nach dem Erstellen des Containers können wir mit dem Befehl
nun die Konfiguration des Containers ansehen. Auch hier finden wir das konfigurierte Volumen:
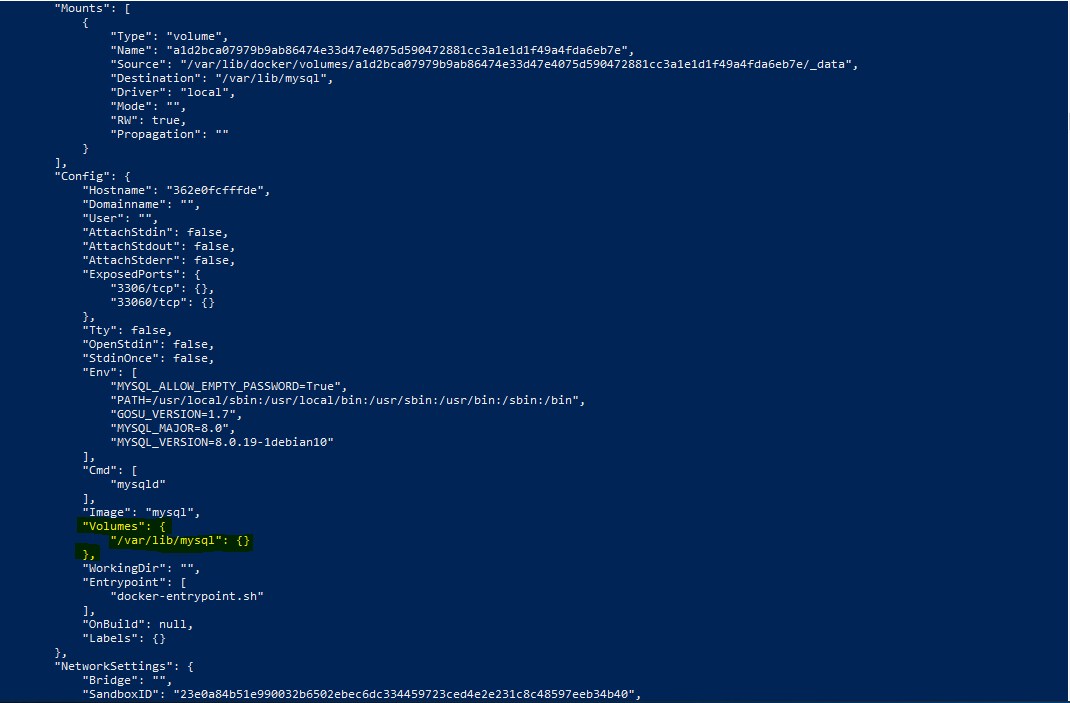
Allerdings können wir hier noch deutlich mehr Informationen zu dem spezifizierten Volumen finden. Betrachten wir hierfür den Abschnitt ‘Mounts’:
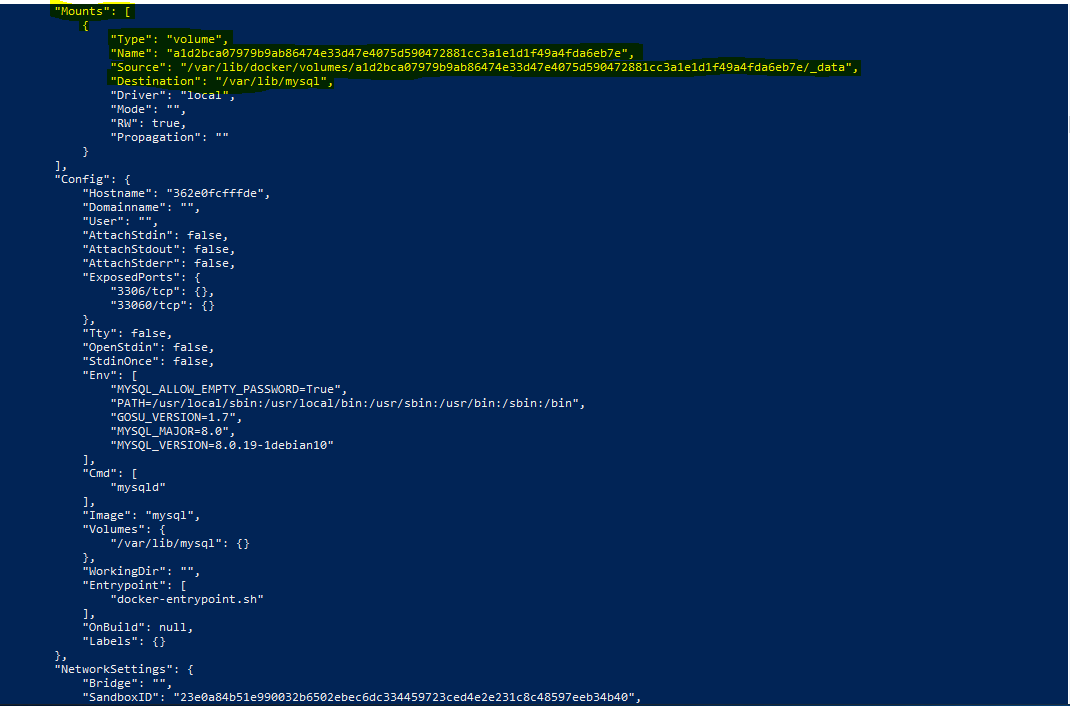
Hier wird nun der tatsächliche Speicherort der Daten auf dem Host konfiguriert. Die sehr lange Zeichenkette hinter ‘Source’ bezeichnet den tatsächlichen Speicherort der Daten auf dem Host. Daten, die also innerhalb des Containers unter dem spezifizierten Volumen /var/lib/mysql abgelegt werden, werden tatsächlich auf dem Host in dem hier erstellten Directory gespeichert.
Wir haben nun also sowohl das Volumen, als auch den Pfad selbst gesehen, in welchem Docker Daten ablegt. Nun wird verdeutlicht, dass diese Daten auch bestehen bleiben, wenn der Container gelöscht wird.
Wir erstellen nun einen zweiten Container mit dem Namen test2. Mit dem Kommando

können wir nun unsere laufenden Container einsehen.
Mit dem Kommando

können wir unsere existierenden Volumes einsehen.
Löschen wir nun unsere beiden Container mit dem Kommando
und betrachten erneut unsere Volumes, stellen wir fest, dass diese immer noch existieren. Unsere Daten gehen also auch beim Löschen eines Containers nicht verloren.

Nun haben wir allerdings noch das Problem, dass wir unsere Volumen aufgrund ihrer sehr komplizierten Namen nicht gut auseinander halten können. Hierfür können wir nun ‘named volumes’ verwenden und unseren Volumes eigene Namen geben
Mit dem Kommando
können wir einen neuen mysql Container erstellen und dem vorkonfigurierten Volume einen Namen geben:

Fazit
Volumes bieten eine sehr gute Möglichkeit, wichtige Daten auch nach dem Ableben eines Containers, zu behalten und in folgenden Containern weiterhin zu verwenden. Mit der Möglichkeit, dem Volumen einen Namen zu geben, können sensible Daten einfach überwacht und verwaltet werden.
Führt man auf einem Container also Anwendungen aus, welche einzigartige Daten erzeugen, die auch beim Wechsel auf eine aktualisierte Version erhalten bleiben sollen, sind Volumes die beste Wahl.




