SQL Server Prozessoraffinität festlegen

Einer der wichtigsten Aspekte, wenn es um Performanz eines SQL Servers und die richtige Nutzung der verfügbaren Hardware geht, ist die Prozessoraffinität. Im folgenden wollen wir die Vorteile der Konfiguration einer Prozessoraffinität und den damit einhergehenden Nebenwirkungen diskutieren.
Was ist eine Prozessoraffinität?
Wenn eine standardmäßige Konfiguration für den Betrieb eines SQL Servers verwendet wird, werden alle verfügbaren CPU Kerne für die Verarbeitung einer Abfrage verwendet. Verschiedene Scheduler regeln dabei die Verteilung der Last auf die einzelnen Kerne. Mit Hilfe der Scheduler wird eine Abfrage-Zustand-Maschine (engl. Query State Machine) implementiert, die zwischen den Zuständen RUNNING, SUSPENDED und RUNNABLE wechselt.
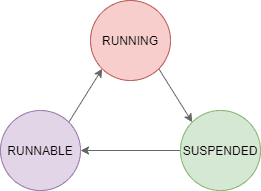
in interessanter Aspekt der Scheduler ist, dass Sie mit Hilfe ihrer SUSPENDED und RUNNABLE Zustände dafür verwendet werden, die Wartezeiten von Abfragen zu bestimmen. Diese Statistik kann viel Einsicht in die Verarbeitung des SQL Servers liefern und lässt uns erkennen, warum Abfragen gegebenenfalls langsam verarbeitet werden.
Der nächste, wichtige Punkt den man für Scheduler beachten muss ist, dass Sie nicht an einen spezifischen Kern gebunden sind, sondern jeder Scheduler beliebige Kerne einer CPU ansprechen kann.
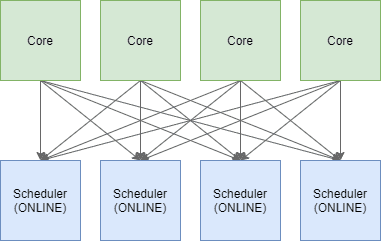
Immer wenn eine Abfrage ausgeführt wird, kann der Scheduler auf jedem verfügbaren Kern aufgeführt werden. Eine 1:1 Beziehung zwischen Scheduler und CPU Kernen existiert also nicht. Der folgende Screenshot zeigt die CPU Auslastung einer Single-Threaded Abfrage deren Arbeitslast sich zum größten Teil auf die CPU beschränkt:
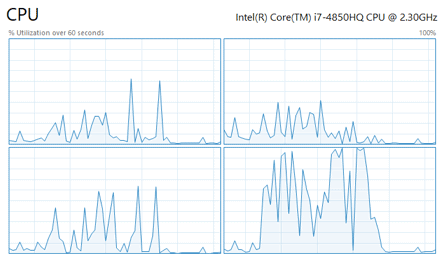
Wie wir sehen können, wird die Arbeitslast der Abfrage auf die vier verfügbaren Kerne verteilt, damit keiner der Kerne unter eine kontinuierliche Auslastung von 100% laufen muss. Mit der folgenden Abfrage können wir anhand der SPID bestimmen, auf welchen CPU Kernen eine bestimmte Abfrage ausgeführt werden kann.
SELECT r.session_id,
t.affinity
FROM sys.dm_exec_requests r
JOIN sys.dm_os_workers w
ON w.task_address = r.task_address
JOIN sys.dm_os_threads t
ON t.worker_address = w.worker_address
WHERE r.session_id = 57Um die obige Abfrage und ihre Rückgabewerte zu verstehen, bleiben wir zunächst bei unserem SQL Server, der vier unterschiedliche CPU Kerne zur Verfügung hat. Wird die Abfrage auf diesem System ausgeführt, würden wir als Ergebnis den Wert 15 bekommen. Um das Ergebnis richtig interpretieren zu können, müssen wir die Zahl in binäre Darstellung umrechnen. Wir erhalten also 1111:
1*2^0 = 1,
1*2^1 = 2,
1*2^2 = 4,
1*2^3 = 8;
1 + 2 + 4 + 8 = 15Diese binäre Zahl kann wiederum als eine Art Flagge interpretiert werden, bei der jede Stelle für einen bestimmten CPU Kern steht. Entsprechend einer 1 oder einer 0 an den jeweiligen Stellen wird vom System gekennzeichnet, ob dieser Kern für die Abfrage verwendet werden kann. In unserem Beispiel (1111) können also alle vier Kerne für die Abfrage verwendet werden.
Prozessoraffinität anpassen
Nun könnten wir uns vorstellen, dass wir je nach Situation und Verwendung unseres SQL Servers nicht immer alle CPU Kerne verwenden wollen. In diesem Fall können wir den Server so konfigurieren, dass nur eine Teilmenge der Kerne verwendet wird.
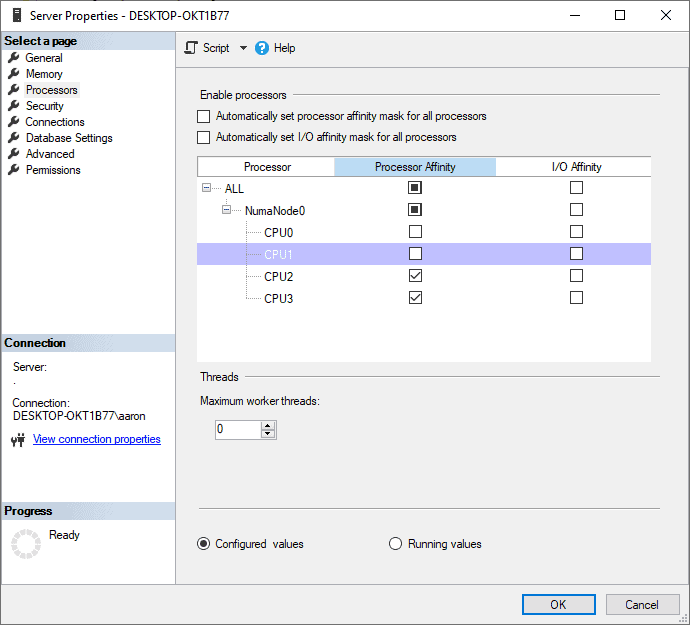
In der oben gezeigten Konfiguration der CPU Kerne haben wir den SQL Server so angepasst, dass nur Kerne 2 und 3 verwendet werden. Die Kerne 0 und 1 sollen nicht berücksichtigt werden. Eine solche Anpassung bietet vor allem für den Betrieb mehrerer Instanzen auf einem SQL Server einen entscheidenden Vorteil. Wenn wir diese Konfiguration anwenden, wird der SQL Server zunächst den Scheduler von Kern 0 und 1 offline schalten.
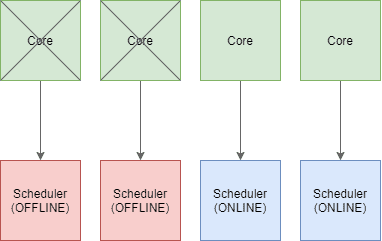
An dieser Stelle kommen wir zu den zuvor erwähnten Nebenwirkungen, die im Zusammenhang mit einer Prozessoraffinität auftreten. Wir stellen also nicht nur ein, dass nur die Kerne 2 und 3 verwendet werden sollen, sondern haben zusätzlich eine Prozessoraffinität erstellt, die folgende Restriktionen mit sich bringt:
- Scheduler 2 kann jetzt ausschließlich auf CPU Kern 2 laufen und
- Scheduler 3 kann jetzt ausschließlich auf CPU Kern 3 laufen
Wenn wir nun unsere Test-Abfrage ausführen, werden wir eine komplett unterschiedliche Verteilung der Arbeitslast erhalten. Auch unsere diagnostische Abfrage für die verwendeten CPU Kerne wird ein völlig unterschiedliches Ergebnis liefern. In dem Fall, dass wir 2 von 4 CPU Kernen konfiguriert haben, würden wir eine 4 oder eine 8 als Ergebnis erwarten. Ins Binärsystem umgerechnet, entspricht dies also 0100 bzw. 1000.
Unsere Scheduler sind nun also direkt an die jeweiligen CPU Kerne gebunden. Der Scheduler kann sich nicht mehr für einen beliebigen Kern entscheiden. Dieses verhalten lässt sich über eine Visualisierung der CPU Auslastung (z.B. mit dem Task Manager) bestätigen:
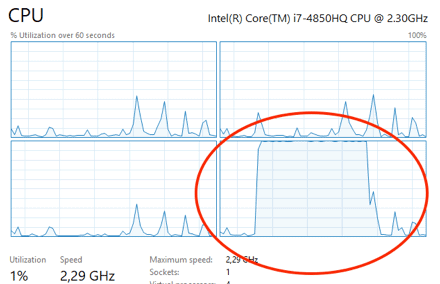
Wir sehen, dass Kern 2 oder 3 nun wesentlich mehr Last zu verarbeiten hat, währen die restlichen Kerne relativ unausgelastet bleiben. Der Grund, warum wir an dem obigen Beispiel keine Verteilung der Last auf die beiden Verfügbaren Kerne sehen, ist ein besonderer: In manchen Fällen kann es dazu kommen, dass ein CPU Kern von einem anderen, arbiträren Prozess blockiert wird und damit die Ausführung der Abfrage behindert.
Stellen wir uns also vor, dass eine weitere Anwendung im Hintergrund läuft und einen unserer beiden verfügbaren Kerne voll beansprucht, kann der SQL Server diesen Kern evtl. nicht verwenden und muss stattdessen die Last auf die verfügbaren Kerne (in diesem Fall nur einer) verteilen. Die Verarbeitungszeit der einzelnen Abfragen wird damit natürlich vergrößert. Ein wichtiger Aspekt, der in der Konfiguration der Prozessoraffinität dringend berücksichtigt werden muss!
Ungewünschte Nebenwirkungen verhindern
Um zu verhindern, dass durch die Limitierung der CPU Kerne eine Affinität zwischen Scheduler und CPU Kern entsteht, können wir uns Trace Flag 8002 zu Hilfe nehmen. Wenn wir diese einschalten (und den SQL Server neu starten, damit die Änderung angewendet wird), werden die Kerne 0 und 1 (bzw. die Scheduler der Kerne) wieder offline geschaltet. Dieses mal entsteht jedoch keine 1:1 Beziehung zwischen Scheduler und CPU Kern.
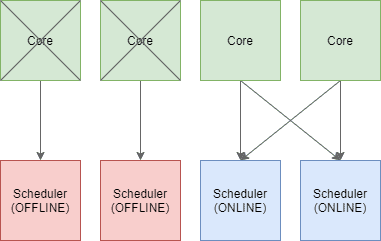
Führen wir unsere Abfrage erneut aus, können wir klar beobachten, dass der Scheduler nun wieder die Last beliebig auf den verfügbaren CPU Kernen verteilen kann. Wir können dieses Verhalten wieder mit Hilfe des Task Managers nachvollziehen:
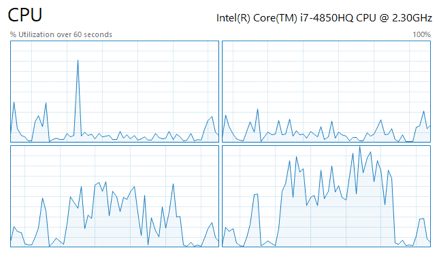
Im Vergleich zu der vorherigen Ausführung, können wir klar erkennen, dass die Last nun besser auf den beiden CPU Kernen verteilt wird. Führen wir unsere diagnostische Abfrage erneut aus, erwarten wir dieses Mal den Wert 12, oder binäre 1100. Der Scheduler kann also Kern 2 ODER 3 für die Ausführung verwenden.
Zusammenfassung
In einer standardmäßig konfigurierten SQL Server Umgebung gibt es keine Prozessoraffinität oder Limitierung für die Verwendeten CPU Kerne. Sobald wir aber beginnen, die SQL Server CPU Kerne zu limitieren, haben wir ein Prozessoraffinität die unsere Scheduler an spezifische CPU Kerne bindet. Diese (teilweise unerwünschten) Nebenwirkungen müssen erkannt werden und können durch die Verwendung der Trace Flag 8002 behoben werden.
Unsere Expert:innen stehen Ihnen bei allen Fragen rund um Ihre IT Infrastruktur zur Seite.
Kontaktieren Sie uns gerne über das
Kontaktformular und vereinbaren ein unverbindliches
Beratungsgespräch mit unseren Berater:innen zur
Bedarfsevaluierung. Gemeinsam optimieren wir Ihre
Umgebung und steigern Ihre Performance!
Wir freuen uns auf Ihre Kontaktaufnahme!
55118 Mainz
info@madafa.de
+49 6131 3331612
Freitags:

