Postgres-Statistiken mit Hilfe von Snapshots analysieren

Datenbankanwendungen sind lebendige Systeme, die sich auf unerwartete Weise verhalten können.
Deshalb ist es wichtig, sich über den Workload zu informieren und zu verstehen, wie eine Postgres-Instanz abgefragt wird.
Es gibt viele Gründe, warum diese Daten nützlich sein können. Schauen wir uns jedoch einige Beispiele an und gehen auf einige Skripte ein, mit denen Sie diese zu etwas Nützlichem zusammenfassen können.
Besuchen Sie zunächst die Toolbox von pgCraftsman, um ein benutzerfreundliches Snapshot-Skript zu finden. Dieses Skript ist so konzipiert, dass es vollständig in sich geschlossen ist. Es wird mit jeder gewünschten Häufigkeit ausgeführt und speichert Snapshots der kritischen Überwachungstabellen direkt in Ihrer Datenbank. Es sind sogar einige Berichtsfunktionen enthalten, mit denen Sie Statistiken im Laufe der Zeit anzeigen lassen können.
Wie gehen Sie vor
Im Postgres Katalog gibt es eine Reihe kritischer Tabellen und Ansichten, die Sie im Auge behalten sollten. Dies ist keine vollständige Liste – sondern eine gekürzte – die das Toolbox-Skript bereits überwacht.
- pg_stat_activity
- pg_locks
- pg_stat_all_tables
- pg_statio_all_tables
- pg_stat_all_indexes
- pg_stat_database
Diese Tabellenansichten enthalten Laufzeitstatistiken zum Verhalten Ihrer Anwendung in Bezug auf das Datenmodell. Das Problem bei vielen davon ist, dass sie entweder point-in-time (wie pg_stat_activity ) oder kumulativ ( pg_stat_all_tables.n_tup_ins enthält die kumulative Anzahl von Einfügungen seit pg_stat_database.stats_reset ) sind. Um aus diesen Laufzeitleistungsansichten nützliche Informationen zu erhalten, sollten Sie diese regelmäßig als Snapshot erstellen und die Ergebnisse speichern.
Der einfachste Weg, um im Laufe der Zeit einige schnelle Statistiken zu generieren, ist das PgCraftsman Toolbox-Skript: pgcraftsman-snapshots.sql.
Angenommen, wir haben einen Workload, von dem wir nichts wissen. Mit pgcraftsman-snapshots.sql können Sie den Workload ermitteln, um den besten Weg zu finden, diesen zu verarbeiten.
Snapshots
Um aus den kumulativen oder point-in-time Überwachungsansichten eine umsetzbare Überwachung zu erstellen, müssen wir die Daten regelmäßig als Snapshot erstellen und zwischen diesen Snapshots vergleichen. Dies ist genau das, was das Skript pgcraftsman-snapshots.sql macht. Alle Snapshots werden in entsprechenden Tabellen in einem neuen ‘Snapshots’-Schema gespeichert.
Die ‘Snapshot’-Funktion führt einfach ein INSERT als SELECT aus jeder der Überwachungsansichten aus. Jede Zeile ist mit der ID des aufgenommenen Snapshots verknüpft ( snap_id ). Wenn alles zusammengesetzt ist, können wir leicht die Anzahl der Einfügungen sehen, die in einer bestimmten Tabelle zwischen zwei Snapshots stattgefunden haben, das Wachstum (in Bytes) einer Tabelle über Snapshots oder die Anzahl der Index-Scans für einen bestimmten Index. Im Wesentlichen alle Daten in einer der Überwachungsansichten, die wir als Snapshot erstellen.
Ausführen des Skripts
Zunächst besteht die Möglichkeit das pgcraftsman-snapshots.sql zu installieren und im Anschluss in einer Datenbank auszuführen.
Eine andere Möglichkeit besteht darin, das Skript in der PostgreSQL-SQL Shell auszuführen. Dies bietet sich vor allem als Alternative zu Docker Containern an, da sich das Skript in der SQL Shell am Einfachsten ausführen lässt. Wir haben uns für diesen Weg entschieden und im folgenden Screenshot können Sie sehen, wie die ersten Zeilen nun aussehen sollten:
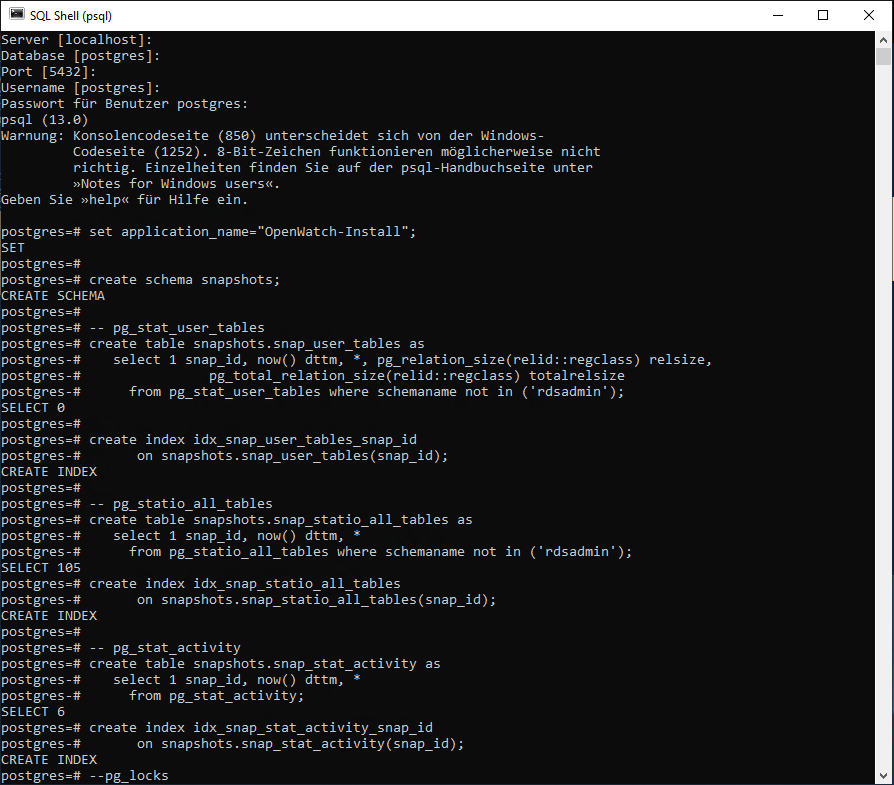
Zusätzlich zur Installation des Snapshot-Schemas erstellt dieses Skript zwei erste Snapshots für Sie. Sie können die Snapshots überwachen, indem folgendes ausgeführt wird:

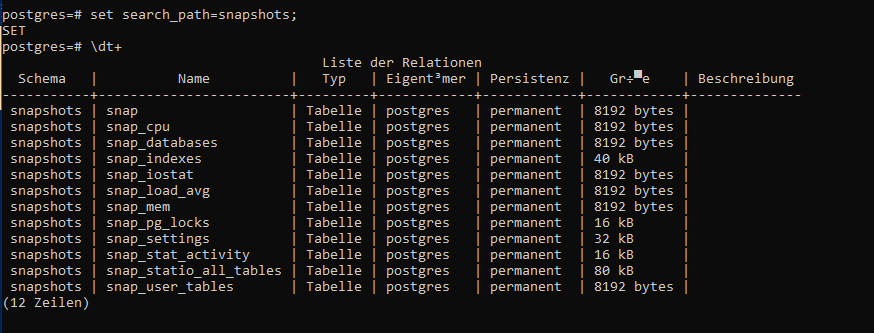
Mit folgendem Befehl kann das Schema auch genauer angesehen werden:
So erstellen Sie einen Snapshot
Die in pgcraftsman-snapshots.sql enthaltene Funktion snapshots.save_snap() speichert alle Metadaten und weist allen eine neue snap_id zu:

Die Ausgabezeile ist die snap_id, die gerade generiert und gespeichert wurde.
Jedes Mal, wenn Sie einen Snapshot erstellen möchten, rufen Sie dafür einfach folgenden Befehl auf:
select snapshots.save_snap();Snapshot-Leistung
Fragen zur Leistung eines Snapshots sind sehr sinnvoll. Sie können sich save_snap() im Code ansehen und werden sehen, dass die Laufzeit des Prozesses von der Anzahl der Zeilen in jeder der Katalogtabellen abhängt. Dies wiederum hängt ab von:
- pg_stat_activity
- pg_locks
- pg_stat_all_tables
- pg_statio_all_tables
- pg_stat_all_indexes
- pg_stat_database
Bei Datenbanken mit Tausenden von Objekten sollten Snapshots häufig bereinigt werden, damit der Snapshot-Mechanismus selbst keine Leistungsprobleme verursacht.
Alte Snapshots bereinigen
Das Bereinigen alter Snapshots mit diesem Skript ist sehr einfach. Es gibt eine Beziehung zwischen der Tabelle snapshots.snap und allen Anderen, daher können Sie mit einem einfachen
DELETE FROM snapshots.snap WHERE snap_id = x;alle Zeilen mit der angegebenen snap_id löschen.
Den Workload überprüfen
Lassen Sie uns ein wenig über den Workload lernen, der in der Datenbank ausgeführt wird. Nachdem wir vor dem Workload einen Snapshot ( snap_id = 3 ) erstellt haben, lassen wir den Workload ein wenig laufen, erstellen dann einen weiteren Snapshot und vergleichen den Unterschied.
Hinweis: Snapshots lesen nur die wenigen Katalogtabellen, die wir oben notiert haben und speichern die Daten. Sie starten keinen Prozess und führen nichts aus. Das Einzige, was einen Snapshot lange laufen lässt ist, wenn Sie eine große Anzahl von Objekten (Schema, Tabelle, Index) in der Datenbank haben.
Einen ‘post-workload’ Snapshot erstellen
Nachdem wir die Arbeitslast eine Weile laufen lassen, erstellen wir einen neuen Snapshot. Dadurch wird der neue Datenstatus gespeichert und wir können die Vorher- und Nachher-Statistiken vergleichen:

Analysieren Sie den Bericht
Es gibt zwei Funktionen für die Berichterstellung über die gesamte Arbeitslast:
select * from snapshots.report_tables(start_snap_id, end_snap_id);
select * from snapshots.report_indexes(start_snap_id, end_snap_id);Beide Berichte benötigen eine Start- und Ende- snap_id. Die erhalten Sie, indem Sie die Tabelle snapshots.snap untersuchen:

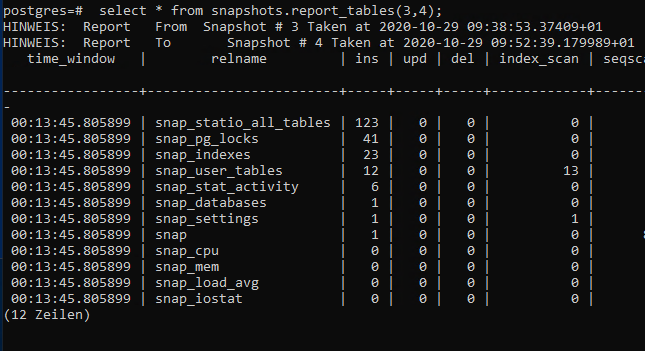
Unser Snapshot vor dem Workload war snap_id = 3 und unser Snapshot nach dem Workload war snap_id = 4 .
Da wir zwei Snapshots untersuchen, können wir genau sehen, was zwischen ihnen passiert ist. Die Anzahl der Einfügungen / Aktualisierungen / Löschungen / sequentiellen Scans / Index-Scans und sogar des Tabellenwachstums. Der Schlüssel ist, dass genau dies zwischen den Schnappschüssen stattgefunden hat. Sie können jederzeit einen Snapshot erstellen und eine beliebige Anzahl von Berichten untersuchen.
Hier sehen Sie einen Ausschnitt des Berichts:
Dieses Skript ist ein Baustein, der Ihnen helfen kann Statistiken zu erstellen, um einzelne Datenbanken zu untersuchen.
Sie sollten nun mit Hilfe dieses Skripts dazu in der Lage sein, Snapshots zu erstellen, abrufen und überprüfen zu können.
Unsere Expert:innen stehen Ihnen bei allen Fragen rund um Ihre IT Infrastruktur zur Seite.
Kontaktieren Sie uns gerne über das
Kontaktformular und vereinbaren ein unverbindliches
Beratungsgespräch mit unseren Berater:innen zur
Bedarfsevaluierung. Gemeinsam optimieren wir Ihre
Umgebung und steigern Ihre Performance!
Wir freuen uns auf Ihre Kontaktaufnahme!
55118 Mainz
info@madafa.de
+49 6131 3331612
Freitags:

