MERGE Abfrageplan in SQL Server

Mit SQL Server 2008 veröffentlichte Microsoft die MERGE Statements als Alternative zu der bestehenden “löschen / updaten / einfügen” Logik. Schon zur Veröffentlichung hatte der Befehl einige Probleme, die auch im Jahr 2021 noch bestehen. Trotzdem kann MERGE einige interessante Vorteile bieten, sollte aber nur mit äußerster Vorsicht in einer produktiven Umgebung verwendet werden.
In den folgenden Abschnitten werden wir einen Blick auf den MERGE-Befehl werfen, einen simplen Test erstellen und nachvollziehen, wie die einzelnen Elemente des Ausführungsplans zum gewünschten Ergebnis kommen. Die von uns betrachteten Details sind aber nicht nur für MERGE relevant, sondern sollen das generelle Verständnis der Verarbeitung von Ausführungsplänen erweitern.
Das Szenario
Für den folgenden Artikel betrachten wir das simple, aber perfekt für MERGE geeignete Szenario, in dem wir eine Tabelle mithilfe von MERGE mit den Daten einer anderen Tabelle synchronisieren wollen: neue Produkte müssen hinzugefügt werden, modifizierte Daten angepasst und nicht länger verfügbare Produkte entfernt werden.
Die Tabellen
Um das zuvor beschriebene Szenario darzustellen, nehmen wir uns zwei Tabellen zur Hilfe. Als Erstes entwerfen wir die Tabelle die synchronisiert werden soll. Sie enthält fiktive Produkte die in unserer Datenbank registriert sind:
CREATE TABLE dbo.Products (
ProductCode char(5) NOT NULL PRIMARY KEY,
ProductName varchar(40) NOT NULL UNIQUE,
Price decimal(9, 2) NOT NULL,
TotalSold int NOT NULL,
Is_Deleted char(1) NOT NULL DEFAULT ('N'),
CONSTRAINT CK_Is_Deleted CHECK (Is_Deleted IN ('Y', 'N')));Als nächstes brauchen wir noch die Staging-Tabelle. Bei dieser Tabelle nehmen wir an, dass sie beispielsweise Daten, die von einer externen Quelle importiert wurden, enthält. Zusätzlich nehmen wir an, dass jedes existierende Produkt in der Staging-Tabelle enthalten sein muss. Ist ein Produkt nicht aufgeführt, gehen wir davon aus, dass es nicht länger verfügbar ist. Die Staging-Tabelle hat folgende Gestalt:
CREATE TABLE dbo.StagingProducts (
ProductCode char(5) NOT NULL PRIMARY KEY,
NewProductName varchar(40) NULL, -- NULL means no change
Price decimal(9, 2) NOT NULL); -- Always includedDas MERGE-Statement
Um die Daten von der Tabelle dbo.Products in die Tabelle dbo.StagigProducts zu importieren, verwenden wir das folgende Statement:
MERGE
INTO dbo.Products AS p
USING dbo.StagingProducts AS sp
ON sp.ProductCode = p.ProductCode
WHEN MATCHED
THEN UPDATE
SET Price = sp.Price,
ProductName = COALESCE(sp.NewProductName, p.ProductName)
WHEN NOT MATCHED BY TARGET
THEN INSERT (ProductCode, ProductName, Price, TotalSold)
VALUES (sp.ProductCode, sp.NewProductName, sp.Price, 0)
WHEN NOT MATCHED BY SOURCE AND p.TotalSold = 0
THEN DELETE
WHEN NOT MATCHED BY SOURCE
THEN UPDATE
SET Is_Deleted = 'Y';Wenn man mit dem MERGE-Syntax vertraut ist, sollte es sehr leicht sein zu verstehen, wie das Skript arbeitet: Falls ein Produkt in beiden Tabellen vorkommt, wird der Preis des Produkts mit dem Wert aus der Staging-Tabelle aktualisiert. Falls sich der Name des Produkts verändert hat, wird auch diese Neuerung übernommen. Ein Produkt das nur in der Staging-Tabelle vorkommt ist neu und wird in die Products Tabelle aufgenommen. Analog wird ein existierendes Produkt, das nicht in der Staging-Tabelle enthalten ist, aus der Products Tabelle entfernt.
Der Ausführungsplan
Der Ausführungsplan für die zuvor beschriebene Abfrage sieht auf den ersten Blick sehr überwältigend aus:

Um zu verstehen, was hier eigentlich wirklich passiert, betrachten wir die Elemente des Ausführungsplans in kleineren Gruppen. Dabei folgen wir dem Datenfluss und arbeiten uns von rechts nach links.
Die Input-Daten sammeln
Wir fangen ganz rechts bei dem Sammeln der Input-Daten an:
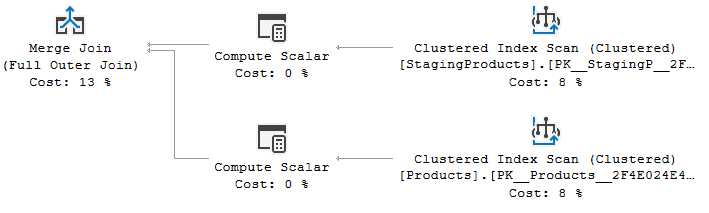
Die Scan-Operatoren
Jeder der beiden in der Abfrage verwendeten Tabellen wird mit einem Clustered Index Scan verarbeitet. Betrachten wir die Prädikat-Eigenschaft, sehen wir, dass keine verwendet wird. Das bedeutet im Umkehrschluss, dass alle Reihen von den Tabellen eingelesen werden müssen.
Dies ist aber nicht immer der Fall. Vor allem für komplexe Abfragen, in denen Filter für die Auswahl der Eingabe verwendet werden, wird der Optimierer unterschiedlich anspruchsvolle Strategien verwenden. Dazugehören beispielsweise die Verwendung eines Scans der Tabelle in Kombination mit einem Prädikat, oder eine Suche.
In unserem simplen Beispiel reicht es, wenn wir uns auf diese Variante beschränken, da der Fokus auf der tatsächlichen Verarbeitung der Abfrage liegen soll. Wir gehen also davon aus, dass alle Einträge von beiden Tabellen als Eingabe für die Abfrage verwendet werden.
Merge Join
Der Merge-Join-Operator auf der linken Seite gehört zum Standard-Repertoir. Die beiden Indexe erzeugen Datensätze, die jeweils nach dem ProductCode sortiert sind. Diese Eigenschaft kann beim Zusammenführen der Datensätze verwendet werden. Das bedeutet, dass an dieser Stelle ein Merge-Join in fast jeder Situation effizienter als ein Nested-Loop oder ein Hash-Match ist.
Der logische Operator des Merge-Joins entspricht einem vollständigen Outer-Join, kann sich aber je nach exakter Verwendung des MERGE Statements verändern. In unserem Fall werden alle drei möglichen Klauseln (MATCHED, NOT MATCHED BY SOURCE, NOT MATCHED BY TARGET) berücksichtigt, was wiederum bedeutet, dass ein vollständiger Outer-Join benötigt wird. Werden weniger Klauseln verwendet, kann es sein, dass im Ausführungsplan stattdessen ein linker oder rechter Outer-Join, bzw. selten auch ein Innerer-Join verwendet werden kann.
Zwei Computed-Scalar-Operatoren
An dieser Stelle fragt man sich vermutlich, was die Aufgabe der zwei Computed-Scalar-Operatoren ist. Wenn ein Computed-Scalar-Operator direkt einem Scan-Operator folgt, liegt das meistens an einer berechneten Spalte innerhalb der Tabelle oder die Abfrage selbst berechnet aus den Spalten der Tabelle einen bestimmten Wert.
Wir wissen bereits, dass unsere Tabelle keine berechneten Spalte enthält. Unsere Abfrage erzeugt ebenfalls keine arbiträren Berechnungen. Ein Blick in die Eigenschaften der Skalare sollte uns also Aufschluss darüber geben können, wieso das Skalar verwendet wird:
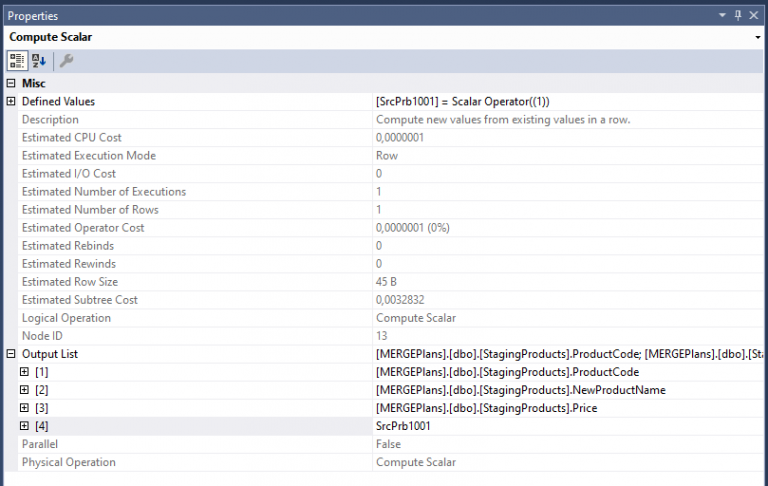
Als Ausgabe des Skalars finden wir in den Eigenschaften, dass das Skalar die drei Spalten von dem Clustered Index Scan auf StagingProducts erhält und diese zusammen mit einer weiteren als SrcPrb1001 bezeichneten Spalte wieder ausgibt. Die Defined Values Eigenschaft dieser Ausgabe zeigt uns, dass es sich bei der berechneten Spalte lediglich um die Konstante 1 handelt.
Im unteren Teil des Baums haben wir eine sehr ähnliche Situation vorliegen. Wieder werden alle Zeilen der Quell-Tabelle eingelesen und anschließend an das Skalar weitergeleitet. Das Skalar gibt die erhaltenen Spalten zusammen mit einer weiteren berechneten Spalte aus. In diesem Fall heißt die berechnete Spalte TrgPrb1003 und hat ebenfalls den konstanten Wert 1.
Generierte Spalten innerhalb es Ausführungs-Plans bestehen immer aus einem eindeutigen mnemonic-code in Kombination mit einer vierstelligen Zahl. Diese mnemonic-codes können oft sehr hilfreich dabei sein zu identifizieren, wofür eine Spalte verwendet wird. In unserem fall steht “SrcPrb” und “TrgPrb” für “source probe” und “target probe”. Sie dienen dazu, anderen Operatoren innerhalb des Ausführungsplans eine Möglichkeit zu geben, zu identifizieren, ob eine Zeile zur Quell- oder Ziel-Tabelle gehört.
Berechnen was zu tun ist
Im nächsten Abschnitt des Ausführungsplans werden vier Computed-Scalar-Operatoren in Reihe ausgeführt. Der Optimierer wäre vermutlich in der Lage gewesen, diese vier Operatoren in nur einen einzigen zu Überführen, der draus resultierende Performanz-Zuwachs wäre jedoch so gering, dass die Optimierung hinfällig wird.
Um die einzelnen Operatoren besser referenzieren zu können, sind sie in der folgenden Grafik nummeriert:

Compute Scalar #11
Da wir dem Datenfluss der Verarbeitung folgen, fangen wir mit unserer Betrachtung wieder ganz rechts, also bei Computed Scalar 11 an. Aus den Eigenschaften des Operators können wir entnehmen, dass der Operator lediglich eine einzelne Spalte mit dem Namen Action1005 berechnet. Spalten, die mit dem Namen Action benannt werden, sind sogennante “action columns”. Sie sind immer in Plänen für MERGE-Statements zu finden.
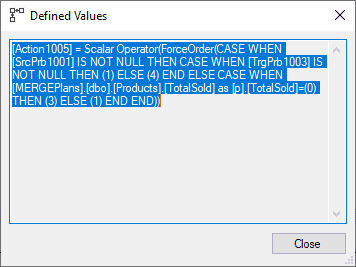
Mit Hilfe dieser action columns werden Modifikation an den Daten decodiert. Die Zuordnung der Codes mit den Aktionen ist leider nicht dokumentiert. Aus unserem Ausführungsplan lässt sich allerdings die folgenden drei Zuordnungen herleiten:
- 1: Update
- 3: Delete
- 4: Insert
Aber auch diese Zuordnung ändert nichts dran, dass die Abfragen in den Defined Values eines Computed Scalar oft sehr schwer zu verstehen sind. Hilfreich kann es dabei sein, die Abfrage in einen Text-Editor zu kopieren und sorgfältig zu betrachten. Zusätzlich können Klammern und Funktionen wie “ForceOrder” entfernt werden, um einen besseren Fokus für die tatsächliche Logik der Abfrage zu bekommen:
Action1005 = CASE WHEN SrcPrb1001 IS NOT NULL
THEN CASE WHEN TrgPrb1003 IS NOT NULL
THEN 1
ELSE 4
END
ELSE CASE WHEN p.TotalSold = 0
THEN 3
ELSE 1
END
END;In diesem Format ist es schon wesentlich leichter nachzuvollziehen, was genau passiert: Mit einem geschachtelten CASE Statement wird zwischen vier unterschiedlichen Zuständen unterschieden. Rollen wir die Situation wieder einmal von hinten auf:
- Action1005 wird auf 1 gesetzt, wenn beide Probe-Spalten einer Zeile nicht NULL sind. Dieser Ausdruck repräsentiert die WHEN MATCHED Klausel. Überprüfen wir unsere vorherige Zuordnung sehen wir, dass der Wert 1 tatsächlich wie zuvor angenommen einem Update entspricht.
- Action1005 wird auf 4 gesetzt, wenn die source probe NULL, aber die target probe nicht NULL ist. D.h., in einer Situation in der eine Spalte in der Quell-Tabelle vorhanden ist, aber nicht in der Ziel-Tabelle (NOT MATCHED BY TARGET), muss eine Einfüge-Operation durchgeführt werden.
- Wenn die source probe NULL ist, muss die target Probe nicht mehr überprüft werden, da der Optimierer weiß, dass aus dem vorherigen Merge-Join nur Zeilen zurückgegeben werden können, die aus einer der beiden Tabellen stammen.
- Interessant ist, dass die Abfrage zwei NOT MATCHED BY SOURCE Klauseln enthält. Eine, mit einer zusätzlichen Überpüfung, ob p.TotalSold = 0 ist, und eine für den verbleibenden Fall. Aus diesem Grund haben wir ein weiteres, geschachteltes CASE Statement welches die Action entweder auf 3 (löschen) oder 1 (update) setzt.
Zusammenfassend kann mal also festhalten, dass der Operator dafür verantwortlich ist, für jede Zeile zu identifizieren, um welche Operation (update, delete, insert) es sich handelt.
Computed Scalar #10
Nachdem mit Computed Scalar #11 identifiziert wurde, welche Operation für die Zeilen ausgeführt werden muss, müssen nun die Ziel-Werte identifiziert werden. Dafür müssen wir die Abfrage im Defined Values des Operators betrachten:
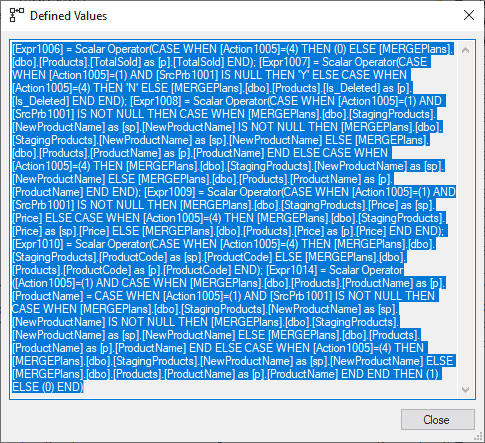
An dieser Stelle wird sehr deutlich, wie unübersichtlich Abfragen aus den Defined Values werden können. Das liegt einerseits daran, dass in dem obigen Statement insgesamt sechs neue Spalten berechnet werden, andererseits aber auch daran, dass die Logik der einzelnen Spalten ebenfalls eher unübersichtlich ist.
Da die Analyse der gesamten Abfrage den Rahmen des Artikel sprengen würde, konzentrieren wir uns an dieser Stelle auf die Expression Expr1008. Formatiert und gekürzt hat sie die folgende Gestalt:
Expr1008 = CASE WHEN Action1005 = 1 AND SrcPrb1001 IS NOT NULL
THEN CASE WHEN sp.NewProductName IS NOT NULL
THEN sp.NewProductName
ELSE p.ProductName
END
ELSE CASE WHEN Action1005 = 4
THEN sp.NewProductName
ELSE p.ProductName
END
END;Das erste CASE Statement betrachtet Action1005 = 1 (update) und die source probe Spalte. Dies wird benötigt, weil es zwei unterschiedliche Situationen für ein Update geben kann: (1) wenn die Werte von zwei Spalten übereinstimmen, oder (2) wenn es keine Übereinstimmung gibt, aber p.TotalSold = 0 definiert ist. Indem wir die source probe überprüfen erkennen wir, dass es sich um den ersten Fall handelt. Also wird Expr1008 auf das Ergebnis des geschachtelten CASE Statements (eine direkte Übersetzung von COALESCE(sp.NewProductName, p.ProductName) aus der original Abfrage) gesetzt. Es wird also deutlich, dass das WHEN des äußeren CASE Statements die Expression für den Produkt-Namen im UPDATE…SET der WHEN MATCHED Klausel liefert.
In der ELSE Klausel wird wieder verschachtelt mit CASE Statements überprüft ob Action1005 einer Insert-Operation (4) entspricht. Ist dies der Fall, wird Expr1008 auf den Wert sp.NewProductName gesetzt. Dies entspricht dem Wert der ProductName-Spalte in der Insert-Aktion des MERGE Statements. In allen anderen Fällen wird Expr1008 auf p.ProductName gesetzt. Dies wird hauptsächlich für die zweite Update-Aktion innerhalb des MERGE statements getan. Der ProductName wird zwar in dieser SET Klausel nicht enthalten, dient aber dafür in einem später auftretenden Clustered Index Merge dafür zu sorgen, dass die Werte erhalten bleiben.
Die meisten der Defined Values verhalten sich sehr ähnlich. Für Expr1006 wird der neue Wert TotalSold gesetzt: entweder 0 oder p.TotalSold; Expr1007 ist entweder “Y” oder “N”, abhängig des momentanen Wertes von Is_Deleted. Expr1009 entspricht entweder sp.Price oder p.Price, Expr1010 entweder p.ProductCode oder sp.ProductCode. Die Werte all dieser Spalten müssen also gesetzt werden, wenn das MERGE Ergebnis entweder ein Update oder ein Insert ist.
Bei der letzten Spalte handelt es sich um Expr1014. Sie ist besonders schwer zu lesen, da sie einerseits die gesamte Abfrage von Expr1008 enthält, andererseits aber auch für T-SQL unzulässigen Syntax benutzt. Eine lesbarere Version der Abfrage könnte so aussehen:
Expr1014 = Action1005 = 1
AND CASE WHEN p.ProductName = Expr1008
THEN 1
ELSE 0
END;Bei Expr1014 handelt es sich um ein Beispiel für interne Spalten die als Boolische-Ausdrücke realisiert werden können. Die Spalte benutzt einen logischen Ausdruck (Action1005 = 1) die zu Wahr oder Falsch ausgewertet werden kann. Das CASE Statement wird anschließend dazu verwendet um zu bestimmen, ob sich der Wert von Expr1008 in der Durchführung im Vergleich zu vorher verändert hat, oder ob der Wert identisch geblieben ist. Bei einer Veränderung wird wieder der Wert True (1) zurückgegeben, sonst False (0). Diese beiden logischen Ausdrücke werden mit einem “AND” verknüpft und anschließend in Expr1014 gespeichert. Das Ergebnis der Spalte Expr1014 ist also “Wahr” (1) wenn die Zeile geupdatet werden soll, aber der Wert für ProductName nicht verändert wurde. In allen anderen Fällen wird False (0) zurückgegeben. Ein wichtiges Detail, dessen Ausmaß in einem der folgenden Abschnitte noch deutlich wird.
Computed Scalar #9 und #8
Die letzten beiden berechneten Skalare stellen sich bei genauerer Betrachtung als eher uninteressant dar. Skalar #9 erzeugt eine Kopie von Expr1014 in Expr1017. Dabei handelt es sich vermutlich um ein Artefakt aus Zwischenschritten der Berechnung des Optimierers.
Bei Skalar #8 erfahren wir aus den Defined Values, dass es zwei Ausdrücke berechnet: Action1005 wird auf den Wert von Action1005 und Expr1017 auf den Wert von Expr1017 gesetzt. Werfen wir einen genaueren Blick in die Ausführung des Plans, bemerken wir, dass Skalar #9 nicht ausgeführt wird, Skalar #8 hingegen schon. Die Laufzeit-Statistik kann helfen, ein noch besseres Verständnis von der Situation zu bekommen: Skalar #8 wird dazu verwendet, die Spalten zu berechnen und die berechneten Werte anschließend zu speichern, bevor mit dem tatsächlichen Aktualisieren von Daten fortgefahren wird. Die Spalten-Werte, die in einem Ausführungsplan verwendet werden, werden allgemein nicht an unterschiedliche Stellen kopiert. Die Operatoren greifen direkt auf den Speicherort der Spalte zu, in den meisten Fällen also auf den Buffer-Pool. Wenn wir nun ein Update auf diesen Daten durchführen, bedeutet das, dass die Werte im Buffer-Pool verändert werden. Da die Definition von Action1005 und Expr1017 von ihren tatsächlichen Werten abhängen, könnte es zur Veränderung in der Auswertung führen.
Die tatsächliche Aufgabe von Computed Scalar #8 ist es also, die unterliegenden Wert der Ausdrücke Action1005 und Expr1017 innerhalb der Zeilen die von Operator zu Operator gereicht werden zu erhalten.
Die Änderungen anwenden
Die dritte Gruppe des Ausführungsplans ist recht klein und im Grunde leicht überschaubar. Sie besteht aus insgesamt zwei Operatoren:

Clustered Index Merge
An dieser Stelle sollte es keine Überraschung sein, einen Clustered Index Merge Operator vorzufinden. Wir suchen ja immerhin nach dem Ergebnis eines MERGE Statements. Um zu verstehen, was die Aufgabe des Operators an dieser Stelle ist, werfen wir einen Blick in die Eigenschaften des Operators:
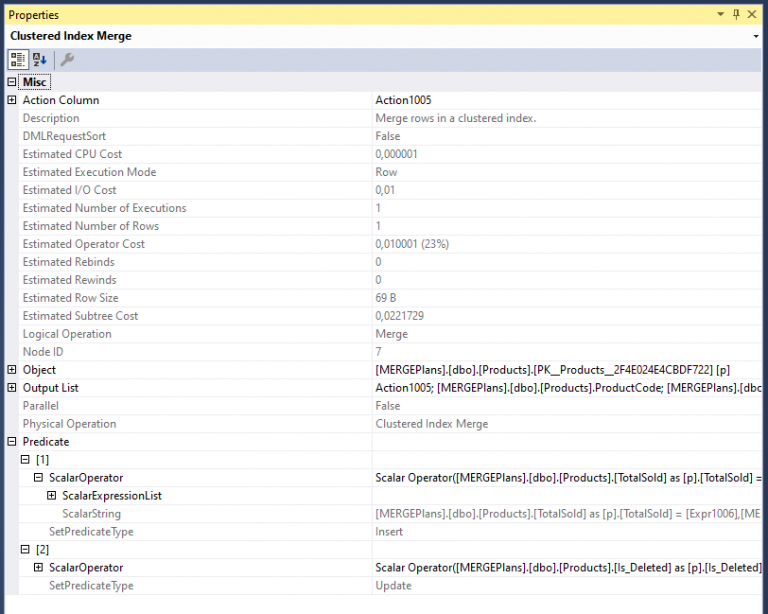
Die Spalte “Action Column” sollte nach unserer sorgfältigen Vorarbeit leicht zu verstehen sein. Der Operator soll die Spalte Action1005 betrachten, um zu entscheiden, was getan werden soll.
Ein wesentlich interessanterer Aspekt ist das Predicate welches vom Operator verwendet wird. Gewöhnlich werden Prädikate dazu verwendet, unerwünschte Spalten aus der Eingabe zu entfernen. Überraschenderweise ist dies für dieses Prädikat nicht der Fall. Tatsächlich existiert gar keine wirkliche Prädikat-Eigenschaft. Je nachdem wie man es sehen will, handelt es sich hierbei eher um ein “Feature” oder einen “Bug”. Werfen wir einen genaueren Blick in das XML welches den Ausführungsplan beschreibt, erkennen wir zwei Eigenschaften mit dem Namen SetPredicate, eines mit der SetPredicateType Eigenschaft “Insert” und eines mit “Update”.
Erweitern wir die Eigenschaften in der Übersicht weiter, erfahren wir, dass das SetPredicate mit der Eigenschaft “Update” drei unterschiedlichen Spalten Werte zuweist: Price, ProductName und Is_Deleted. Für Spalten denen keine NULL-Werte zugewiesen werden dürfen, wird dies mit der internen Funktion RaiseIfNullUpdate durchgeführt, um einen Fehler bei unzulässiger Eingabe hervorzurufen. Das zweite SetPredicate ordnet insgesamt 5 Werte zu: Kopien der drei Werte für Update und zusätzlich ProductCode und TotalSold.
Es sollte nun ersichtlicher sein, welche Aufgabe der Operator verfolgt: Für jede eigelesene Zeile wird bestimmt, ob eine Update-, Delete- oder Insert-Operation durchgeführt werden muss. Im Falle von Insert und Update werden die SetPredicate Eigenschaften verwendet, um die neuen Werte der Spalte zu bestimmen.
Zu guter Letzt werden die Ergebnisse des Operators an den vorausgehenden Knoten (Assert) weitergeleitet.
Assert
Der Assert-Operator kann dazu verwendet werden, ein bestimmtes Constraint zu überprüfen. Um herauszufinden was der Assert-Operator in unserem Beispiel macht, müssen wir die Predicate Eigenschaft des Operators betrachten:
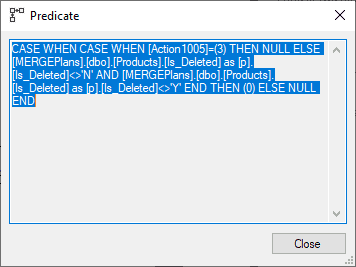
Der erwartete Wert den der Operator zurück geliefert hat, ist NULL. Wird dieser Wert zurückgegeben, gab es keine Probleme (bzw. alle Daten haben dem Constraint entsprochen) und eine Zahl, wenn es zu Problemen gekommen ist. Im zweiten Fall sollte die Abfrage zurückgerollt und ein Fehler ausgegeben werden.
Wie zuvor ist auch diese Abfrage wieder sehr kompliziert, weshalb wir eine vereinfachte Version der eigentlichen Abfrage betrachten:
CASE WHEN CASE WHEN Action1005 = 3
THEN NULL
ELSE p.Is_Deleted <> 'N'
AND p.Is_Deleted <> 'Y'
END
THEN 0
ELSE NULL
END;Hier finden wir ein CASE Statement in unüblicher Form vor. Das Ergebnis des CASE Statements ist gleichzeitig die Eingabe für die WHEN Klausel der äußersten CASE Klausel.
Wenn Action1005 dem Wert 3 entspricht, wurde eine Zeile entfernt. In diesem Fall wird eine NULL zurückgegeben, um einen undefinierten boolschen Wert darzustellen. Für die Fälle Update und Insert wird der Ausdruck “p.Is_Deleted <> ‘N' AND p.Is_Deleted <> 'Y’” ausgewertet.
Zusammenfassend können wir also festhalten, dass das geschachtelte CASE Statement “False” für Update- und Insert-Zeilen zurückliefert. Die Rückgabe ist Unkown (also NULL) falls keine Zeile geupdatet oder eingefügt wurde und “True”, wenn eine Einfüge– oder Update-Operation auf Is_Deleted statt gefunden hat.
Index Pflege
In der vierten und letzten Gruppe des Abfrageplans betrachten wir die Optimierung der Pflege des Nonclustered Index der Tabelle Products.

Der Clustered Index Merge hat bereits dafür gesorgt, dass sich die Daten im Index verändert haben. Sollten wir die Situation nicht bereinigen, würde dies zu Inkonsistenzen führen. Es wird also ein Index Update dazu verwendet, den Index wieder zu bereinigen. Die anderen Operatoren in der Gruppe sind lediglich dafür zuständig, diesen Vorgang zu beschleunigen.
Teilen, Sortieren und Zusammenführen
Die hier verwendete Kombination von Collapse, Sort und Split-Operatoren sind sehr üblich für die Pflege von nonclustered Indexen. Es handelt sich dabei um keine spezifische Eigenschaft von MERGE Statements und wir werden Sie deshalb nur oberflächlich betrachten.
Wenn wir weiterhin dem Daten-Flow des Abfrageplans folgen, ist der erste Operator, dem wir begegnen, ein Split. Der Operator betrachtet die Action-Spalte und entscheidet basierend auf den gefundenen Werten, was zu tun ist. Für Insert- und Delete-Zeilen macht er nichts. Diese Zeilen werden einfach an die Ausgabe weitergeleitet. Update-Zeilen werden dagegen in zwei neue Zeilen aufgeteilt: eine für die Werte vor dem Update, eine für die Werte nach dem Update.
Das Ergebnis des Split-Operators wird anschließend anhand des Index-Schlüssels vom nonclustered Index sortiert. Alleine dieser Schritt kann bei der Index-Aktualisierung einen entscheidenden Unterschied in der Performanz liefern. Hier stellt er allerdings die korrekte Ausführung des letzten Operators sicher.
Der Collapse-Operator sucht nach unmittelbar benachbarten Zeilen in der Eingabe, die einer Delete– und eine Insert-Operation für den selben Schlüssel darstellen und ersetzt diese Zeilen mit einer neuen Zeile die ein Update darstellt.
Filter
In unserem hier betrachteten Beispiel beinhaltet das Split/Sort/Collapse-Pattern einen zusätzlichen Filter Operator zwischen den Elementen. Der Grund hierfür ist, dass so noch mehr Arbeit gespart werden kann.
Das Predicate des Filters ist sehr simpel: NICHT Expr1017. Expr1017 ist eine interne Spalte die einen Boolean repräsentiert, welche den materialisierten Wert von Expr1014 enthält. Dieser Wert wurde in Scalar #10 auf “True” gesetzt, wenn die Zeile von Merge geupdatet werden musste. Das interessante hierbei war, dass der ProductName mit dem identischen Wert geupdatet wurde. Entweder, weil das Update für Is_Delete war, weil NewProductName im Staging-Table als NULL deklariert war oder weil das Produkt in Tabelle und Staging-Tabelle identisch waren.
Der “NOT Expr1017” Filter sorgt an dieser Stelle also dafür, dass alle Zeilen deren ProductName auf einen identischen Wert aktualisiert wurden, entfernt werden. Was übrig bleibt sind alle Delete-, Insert– und Update-Zeilen deren ProductName sich verändert hat. Es werden also nur die Zeilen behalten, bei denen es innerhalb des Index-Schlüssels Veränderungen gab.
Index Update
Die zuvor von Collapse erzeugte Ausgabe wird mithilfe des Index Update Operators verarbeitet. Schauen wir uns die Action Column Eigenschaft des Operators an sehen wir, dass hier wieder die Spalte Action1005 verwendet wird, um zu bestimmen, ob eine Zeile eine Insert-, Delete- oder Update-Operation im Index beschreibt.
Fazit
Einen Ausführungsplan im Detail zu betrachten kann sehr interessant und aufschlussreich sein. Auch wenn Sie selbst MERGE nicht in einer produktiven Umgebung verwenden, kann es dennoch sehr hilfreich sein zu wissen, wie SQL Server den Operator intern verarbeitet.
Unsere Expert:innen stehen Ihnen bei allen Fragen rund um Ihre IT Infrastruktur zur Seite.
Kontaktieren Sie uns gerne über das
Kontaktformular und vereinbaren ein unverbindliches
Beratungsgespräch mit unseren Berater:innen zur
Bedarfsevaluierung. Gemeinsam optimieren wir Ihre
Umgebung und steigern Ihre Performance!
Wir freuen uns auf Ihre Kontaktaufnahme!
55118 Mainz
info@madafa.de
+49 6131 3331612
Freitags:

