Hochverfügbarkeit in ‘Azure Database for PostgreSQL’

Einführung
Wir werden uns in diesem Beitrag mit den in Azure vorhandenen Hochverfügbarkeitsfunktionen befassen.
Datenbanken hosten verschiedene Arten von Datenformaten. Trotz der unterschiedlichen Datentypen, die in Datenbanken gehostet werden können, gibt es einige Aspekte von Datenbanken, die aus Sicht der Datennutzung üblich sind, wie beispielsweise Datensicherheit, Data Governance und Datenverfügbarkeit. Abhängig von der Art der Datennutzung sind einige Formen der Datenverfügbarkeit nicht allzu zeitkritisch und können ohne Zeitdruck verarbeitet und bereitgestellt werden. Aber viele Arten von Daten, typischerweise transaktionale Daten oder Daten, die für die Entscheidungsfindung wichtig sind, können sehr zeitkritisch sein und erfordern eine hohe Verfügbarkeit. Jede Ausfallzeit, die durch Ereignisse wie Serverausfälle, Verbindungsfehler usw. verursacht wird und die Daten nicht verfügbar macht, ist inakzeptabel und hat große Auswirkungen auf das Geschäft. Aus diesem Grund ist Hochverfügbarkeit eines der wichtigsten Merkmale bei der Entwicklung von Datenlösungen.
Um Hochverfügbarkeit zu gewährleisten, werden verschiedene Ansätze wie Datenreplikation und -synchronisation, Server-Failover, DNS-Swapping usw. verwendet, um den Fall zu bewältigen, dass der primäre Server, auf dem die Daten liegen, nicht verfügbar ist. Die allgemeine Lösung, die von fast allen Datenbanken verwendet wird, besteht darin, ein oder mehrere Replikate zu erstellen und diese verfügbar zu machen, wenn der primäre Server ausfällt. Die Azure Cloud-Plattform bietet hierzu eine Vielzahl von Datenbankdiensten wie beispielsweise Azure SQL, Azure Database for MySQL, Azure CosmosDB, Azure Database for PostgreSQL. Dieser Artikel soll Ihnen helfen, die Hochverfügbarkeitsfunktionen für Azure Database for PostgreSQL zu verstehen.
Eine ‘Azure Database for PostgreSQL’-Instanz erstellen
Um die Hochverfügbarkeitsfunktionen in Azure Database for PostgreSQL kennenzulernen müssen wir zunächst eine neue Instanz erstellen. Wir gehen davon aus, dass Sie den erforderlichen Zugang zur Azure-Cloud-Plattform mit den Rechten zur Verwaltung des ‘Azure Database for PostgreSQL’-Dienstes haben. Navigieren Sie zum Dashboard von Azure Database for PostgreSQL und klicken Sie auf die Schaltfläche Erstellen. Es wird, wie unten gezeigt, ein neuer Assistent für die Erstellung der Datenbank aufgerufen. Unser erster Schritt ist die Auswahl der Edition des PostgreSQL-Servers, den wir erstellen möchten. Es werden vier Editionen angeboten – Single Server, Flexible Server, Hyperscale Server und PostgreSQL Hyperscale mit Azure Arc-Unterstützung, wie unten dargestellt.
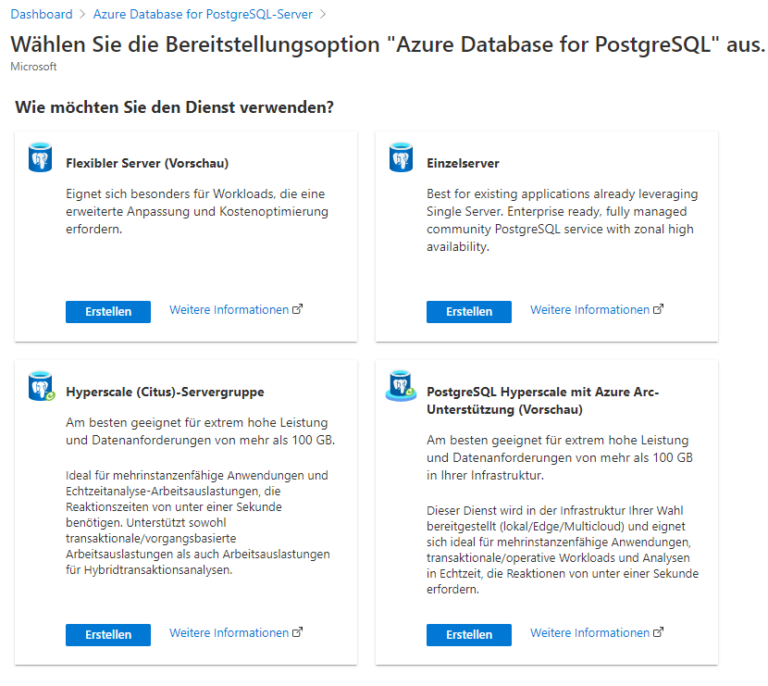
Da wir eine Hochverfügbarkeitskonfiguration erstellen möchten, müssen wir die Option Flexible Server wählen. Die Option Einzelserver bietet zu diesem Zeitpunkt keine Hochverfügbarkeitsfunktionen. Sobald wir die Flexible Server Option ausgewählt haben, werden Sie zur Einrichtung weitergeleitet. Geben Sie die primären Details der Instanz wie Abonnement, Ressourcengruppe, Servername und Region an. Für unseren Anwendungsfall können wir mit der Option Entwicklung fortfahren. Standardmäßig ist Produktion die ausgewählte Option, wie unten gezeigt.
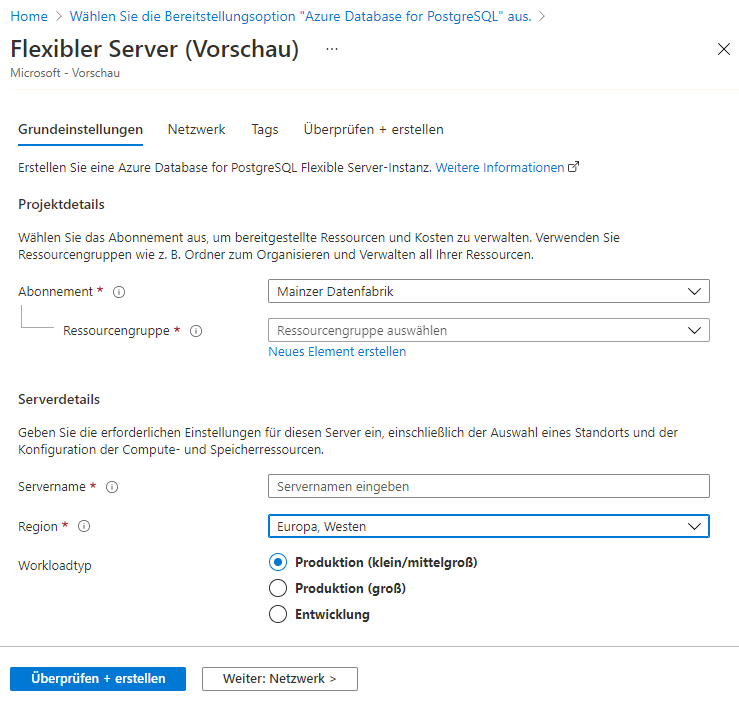
Weiter unten finden Sie die restlichen Details. Wir können die Compute- und Speicherkapazität wie gewünscht auswählen. Für den Moment fahren wir mit den Standardoptionen für Kapazität, Verfügbarkeitszone und PostgreSQL-Version fort.
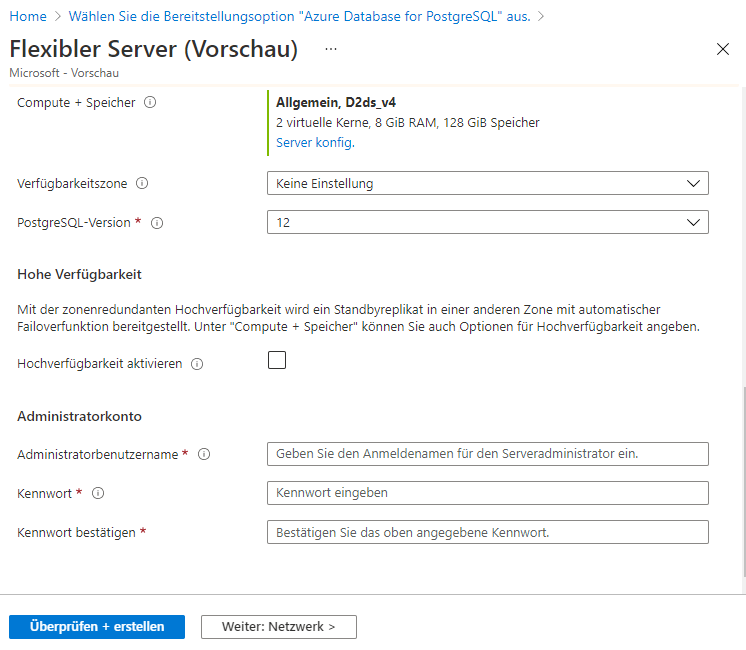
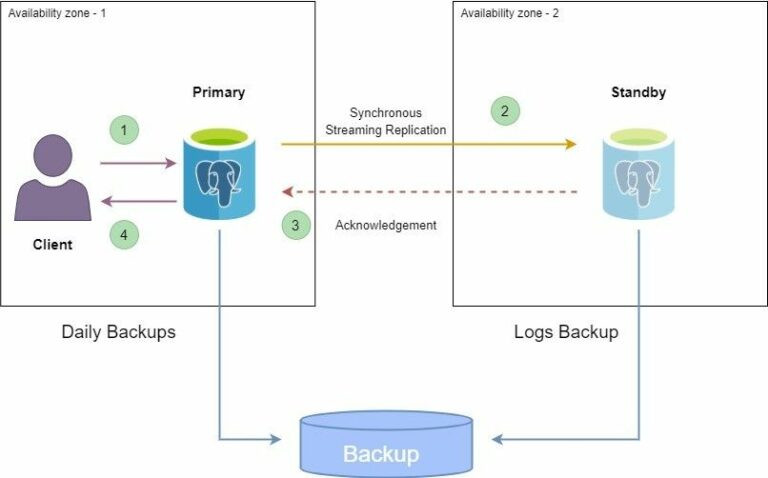
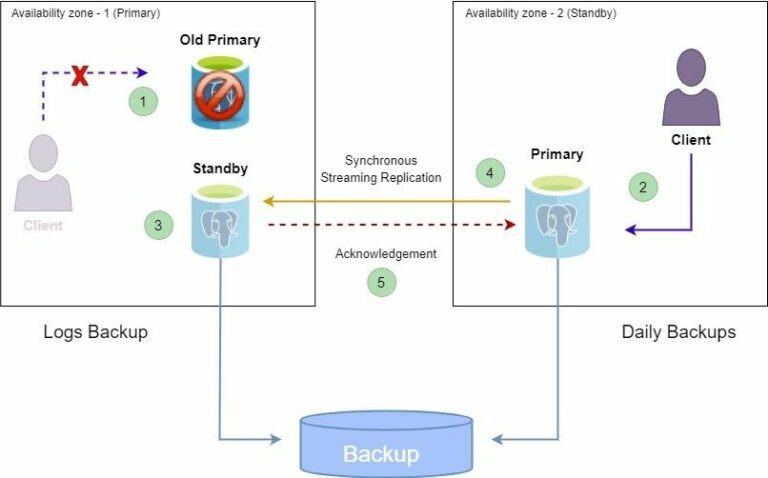
Der nächste Schritt bei der Konfiguration ist der Abschnitt Hochverfügbarkeit. Er ist, wie oben gezeigt, standardmäßig nicht aktiviert. Wenn wir die Hochverfügbarkeitskonfiguration aktivieren, wird eine Standby-Replik der primären Instanz in einer separaten Verfügbarkeitszone mit einer automatischen Failover-Konfiguration erstellt. Dies bedeutet, dass die Replikation und Synchronisation zwischen den primären Instanzen, sowie den Standby-Instanzen vom ‘Azure Database for PostgreSQL’-Dienst verwaltet wird. Die Überwachung der primären Instanz auf Verfügbarkeit und die Umschaltung auf die Standby-Instanz, die auch als Failover bezeichnet wird, erfolgt ebenfalls durch den Azure Database for PostgreSQL Server. Wir haben hier die Möglichkeit auszuwählen, wann ein Failover durchgeführt werden soll. So wie auch die Failover-Erfahrung zu testen, um zu verstehen, was zu erwarten ist und wie man die Systeme verwaltet, die von der Datenbankinstanz abhängig sind, wenn ein Failover stattfindet. Das werden wir uns im letzten Teil dieses Artikels anschauen. Im Folgenden finden Sie eine schematische Darstellung des Hochverfügbarkeits- und Failover-Prozesses.
Nachdem Sie die Hochverfügbarkeitskonfiguration aktiviert haben, geben Sie den Benutzernamen und das Kennwort für die Instanz ein und klicken auf die Schaltfläche Netzwerk. In diesem Abschnitt müssen wir die Netzwerkkonnektivität konfigurieren. Standardmäßig ist der öffentliche Zugriff ausgewählt. Wir können diesen Verbindungsmodus beibehalten, da wir für unser Beispiel eine Verbindung zu dieser Instanz von einem lokalen Rechner aus benötigen. Außerdem müssen wir unseren Rechner, d. h. die Client-IP, zu den Firewall-Einstellungen hinzufügen, um eingehende Verbindungen von unserem lokalen Rechner zu der zu erstellenden Instanz zuzulassen. Nachdem diese Konfiguration abgeschlossen ist, können wir optional Tags zur Instanzkonfiguration hinzufügen und schließlich die Konfiguration überprüfen und die Erstellung der neuen Instanz einleiten.
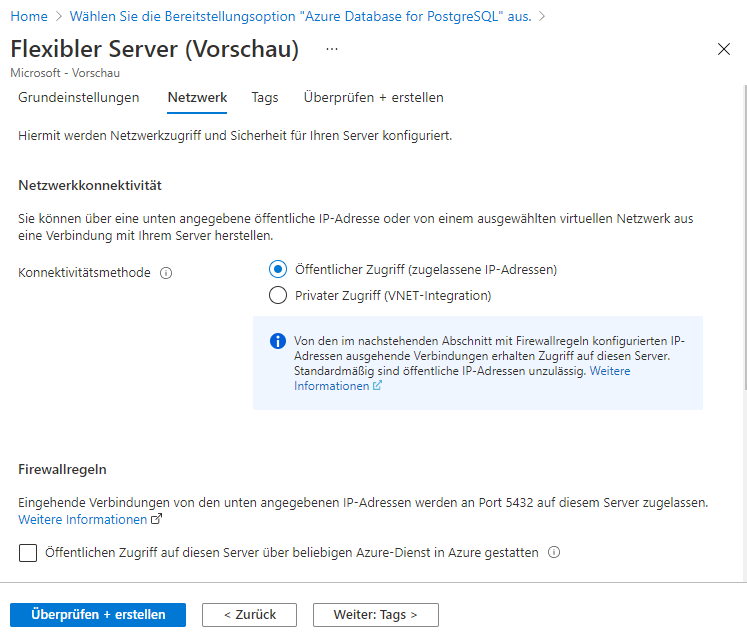
Klicken Sie auf Überprüfen und erstellen, um eine neue Instanz zu erstellen. Es kann ein paar Minuten dauern, bis die Datenbankinstanz mit der aktivierten Hochverfügbarkeitskonfiguration erstellt ist. Nachdem die Instanz erstellt wurde, navigieren Sie zum Dashboard der Instanz. Sie finden im linken Bereich des Dashboards einen Menüpunkt namens Hochverfügbarkeit. Klicken Sie auf dieses Element, damit Ihnen die Details, wie unten zu sehen ist, dargestellt werden.
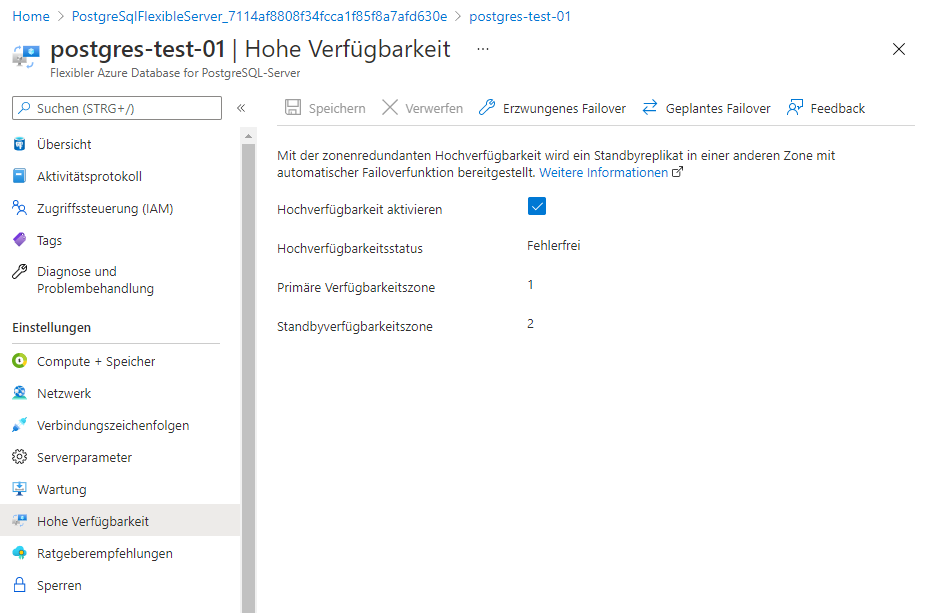
Sobald die Hochverfügbarkeitskonfiguration eingerichtet ist, verlagert sich der Schwerpunkt auf die Planung des Failovers. Ausfallzeiten können sowohl geplant als auch ungeplant sein, je nach den Umständen, die die Ausfallzeit verursachen. Bei einem Failover kann die Verbindung zur primären Instanz nach einer Weile unterbrochen werden. Die nachfolgenden Verbindungen werden dann an die Standby-Instanz weitergeleitet, die nun zur primären Instanz wird und es wird eine neue Standby-Instanz erstellt. Dieser Vorgang wird in dem unten stehenden Diagramm erläutert.
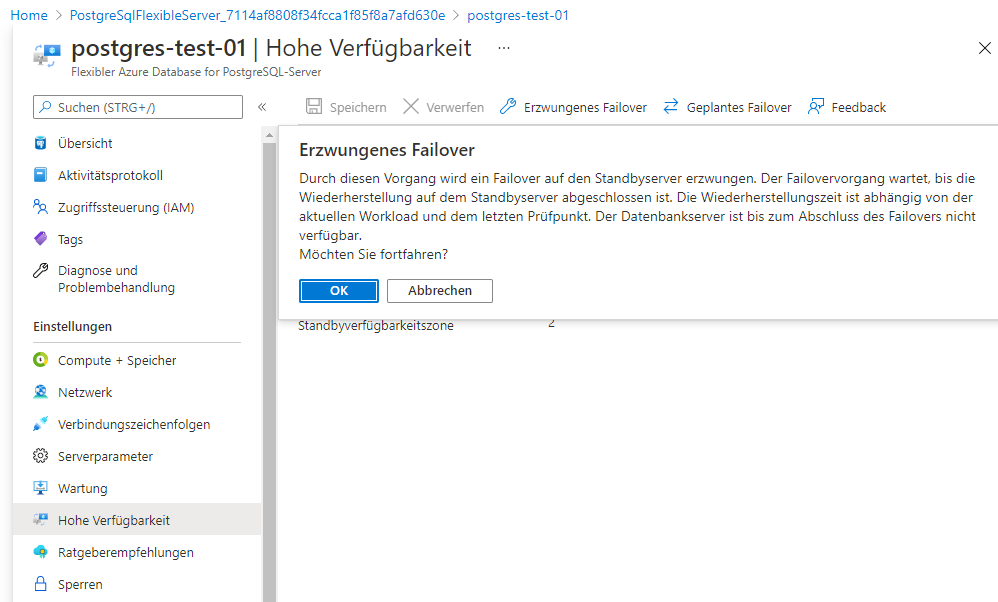
Der oben beschriebene Failover-Prozess findet statt, wenn ein unerwartetes Ereignis eintritt, das die primäre Instanz außer Betrieb setzen würde. Manchmal möchte man aber auch ein geplantes Failover durchführen – um zu testen, wie man im Falle eines Failovers reagiert, oder um ein Failover zu einem geplanten Zeitpunkt durchzuführen, damit die übrigen Systeme nicht durch ein unzeitiges Failover beeinträchtigt werden. Diese Funktionen werden auf der Hochverfügbarkeitsseite angeboten. Nehmen wir an, wir möchten ein erzwungenes Failover initiieren, um zu testen, wie sich das Failover auf die vor- und nachgelagerten Anwendungen auswirkt, die mit Datenpipelines oder direkt mit der Instanz integriert sind. Für eine solche Analyse können wir ein erzwungenes Failover initiieren, indem wir auf die Schaltfläche Erzwungenes Failover klicken. Daraufhin wird ein Popup-Fenster mit den unten abgebildeten Informationen angezeigt.
In dem Pop-up wird deutlich darauf hingewiesen, dass der Failover-Prozess die primäre Instanz auf die Standby-Instanz umschaltet. Es kommt zu einer Ausfallzeit und die Vorlaufzeit für die Wiederherstellung kann je nach den laufenden Operationen und dem letzten Datenbank-Checkpoint variieren. Weiterhin ist die Datenbank in der Zwischenzeit ebenfalls nicht verfügbar. Klicken Sie auf Ok, um zu sehen was passiert, wenn das Failover läuft und notieren Sie die Zeit, die für den Abschluss des Failovers benötigt wird.
Diese neuen Failover-Optionen in ‘Azure Database for PostgreSQL‘ bieten Möglichkeiten zum Testen der Auswirkungen eines Failovers sowie zur Planung des Failovers.
Fazit
In diesem Artikel haben wir die Bedeutung von Hochverfügbarkeit und Datenbank-Failover kennengelernt. Wir haben uns mit der Konfiguration der Hochverfügbarkeit in ‘Azure Database for PostgreSQL’ befasst und die neue Failover-Testoption kennengelernt, die in ‘Azure Database for PostgreSQL’ neu eingeführt wurde, um den Failover-Prozess zu testen und zu planen.
Die Mainzer Datenfabrik ist auf das Gebiet der Azure Datenbanken spezialisiert. Wenn Sie mit dem Gedanken spielen, auf Azure zu migrieren oder einfach eine Performance Beratung benötigen, stehen wir Ihnen gerne mit Rat und Tat zur Verfügung. Schreiben Sie uns gerne über das Kontaktformular und lernen unsere Profis kennen.
Unsere Expert:innen stehen Ihnen bei allen Fragen rund um Ihre IT Infrastruktur zur Seite.
Kontaktieren Sie uns gerne über das
Kontaktformular und vereinbaren ein unverbindliches
Beratungsgespräch mit unseren Berater:innen zur
Bedarfsevaluierung. Gemeinsam optimieren wir Ihre
Umgebung und steigern Ihre Performance!
Wir freuen uns auf Ihre Kontaktaufnahme!
55118 Mainz
info@madafa.de
+49 6131 3331612
Freitags:

