Adaptive Abfrage Verarbeitung in SQL Server 2017

Mit der Veröffentlichung des SQL Servers 2017 wurden grundlegende Änderungen durchgeführt. Und obwohl ein Großteil der Arbeitszeit in die Entwicklung einer SQL Server Version, die auf verschiedenen Linux Distributionen genutzt werden kann, gibt es zusätzlich einige neue interessante Themen und Features. In dem heutigen Artikel wollen wir die adaptive Abfragen-Verarbeitung betrachten.
Um die Verarbeitung von Abfragen zu verbessern, wird vor der Ausführung der Abfrage im Rahmen der Optimierung versucht, die Kardinalität (also die Ranggröße) der einzelnen Schritte des Ausführungsplans zu schätzen. Diese Information (falls akkurat genug geschätzt) kann dazu verwendet werden, beispielsweise die Ausführungsreihenfolge der Operationen anzupassen.
Gelingt es jedoch nicht diesen Wert akkurat genug zu bestimmen, kann dies einige negative Folgen für die Performance der Abfrage bedeuten:
- Ausführungszeit verschlechtert sich
- Überschüssige Verwendung von Ressourcen (CPU, Memory, I/O)
- Sog. “spills” der Daten auf sekundärem Speicher
- etc.
Die neue Familie der adaptiven Abfrage-Verarbeitung bietet drei neue Möglichkeiten für den Umgang mit verschiedenen Arbeitsbelastungen:
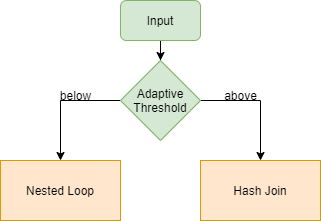
Batch Mode Adaptive Joins
In der allgemeinen Optimierung bei der Ausführung von Join-Operationen gibt es drei Möglichkeiten:
nested loop, merge join und hash match. Welcher dieser Algorithmen angewendet wird, hängt stark von der Kardinalität der Eingabe ab. Wird diese also fehlerhaft ermittelt, kann dies die Auswahl eines unangemessenen Algorithmus nach sich ziehen.
Das neue Batch Mode Adaptive Joins Feature bietet die Möglichkeit die Auswahl des Algorithmus zu verzögern, bis die erste Zeile der Eingabe verarbeitet wurde. Basierend auf einem bestimmten Schwellenwert kann so eine Entscheidung darüber getroffen werden, welche Strategie ausgeführt werden soll. Damit kann der momentane Plan dynamisch zur Laufzeit geändert werden.
Batch Mode Memory Grant Feedback
Ein Abfrage-Verarbeitungsplan beinhaltet stets Angaben bezüglich des minimal benötigten Speicherbedarfs zur Verarbeitung der Abfrage sowie den idealen Speicherbedarf, um alle Ergebnis-Zeilen im primären Speicher darzustellen. Sind diese Angaben ungenau, kann dies zur Minderung der Performance führen. Wird dabei zu viel Speicher zugewiesen, wird Speicher verschwendet. Wird zu wenig zugewiesen, kann es passieren, dass auf den sekundären Speicher zurückgegriffen werden muss.
Im Hinblick auf sich wiederholende Arbeitsbelastungen kann Batch Mode Memory Grant Feedback benutzt werden, um Speicherzuweisungen zu verbessern. Der Speicherbedarf des Plans wird wiederholt berechnet und aktualisiert. Zusätzlich werden die Berechnungen zwischengespeichert, um so Anfragen mit einer ähnlichen Arbeitsbelastung und Abfragenaufbau in Zukunft besser bearbeiten zu können.
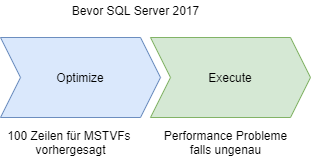
Interleaved Execution for Multi-Statement Table Valued Functions
Die verschachtelte Ausführung von Multi-Statement Table Valued Functions (MSTVFs) verändert die unidirektionale Grenze zwischen Optimierungs- und Ausführungsphase für einzelne Abfragen. Wird während der Optimierung eine potentielle verschachtelte Abfrage erkannt, wird die Optimierung unterbrochen, der anwendbare Unterbaum wird ausgeführt, Kardinalitätseinschätzungen werden gesammelt und anschließend die Optimierung wieder aufgenommen.
Diese verschachtelte Ausführung hilft mit den Performance-Problemen durch die (teilweise) festen Kardinalitäten im Zusammenhang mit Multi-Statement Table Valued Functions. Das Resultat ist ein besser-informierter Ausführungsplan basierend auf echten Arbeistbelastungseigenschaften (engl. workload characteristics).
Neben diesem gibt es natürlich noch eine Vielzahl an weiteren interessanten Änderungen. Für weitere Informationen hierzu können Sie unsere Artikel über die Automatisierte Plan Korrektur und die Showplan Erweiterung auf unserer Website lesen. Eine vollständige Übersicht aller dieser finden Sie hier direkt auf der Microsoft Seite bzgl. des Release von SQL Server 2017.
Unsere Expert:innen stehen Ihnen bei allen Fragen rund um Ihre IT Infrastruktur zur Seite.
Kontaktieren Sie uns gerne über das
Kontaktformular und vereinbaren ein unverbindliches
Beratungsgespräch mit unseren Berater:innen zur
Bedarfsevaluierung. Gemeinsam optimieren wir Ihre
Umgebung und steigern Ihre Performance!
Wir freuen uns auf Ihre Kontaktaufnahme!
55118 Mainz
info@madafa.de
+49 6131 3331612
Freitags:

