3NF, 4NF, 5NF und Star Schema

3NF – Die dritte Normalform
Eine Relation ist in 3NF (dritte Normalform), wenn sie in 2NF (zweite Normalform) ist und keinerlei transitive, partielle Abhängigkeiten besitzt. Also genau dann, wenn mindestens eine der folgenden Konditionen für jede nicht-triviale, funktionale Abhängigkeit “X → Y” gegeben ist:
- X ist ein Superschlüssel (super key)
- Y ist ein primäres Attribut (jedes Element von Y ist teil eines Kandidatenschlüssels)
Um die gegebenen Konditionen zu überprüfen, betrachten wir das folgende Beispiel:
Die Tabelle EMPLOYEE_DETAIL
| EMP_ID | EMP_NAME | EMP_ZIP | EMP_STATE | EMP_CITY |
|---|---|---|---|---|
| 222 | Harry | 201010 | UP | Noida |
| 333 | Stephan | 02228 | US | Boston |
| 444 | Lan | 60007 | US | Chicago |
| 555 | Katharine | 06389 | UK | Norwich |
| 666 | John | 462007 | MP | Bhopal |
Der Superschlüssel der Tabelle:
{EMP_ID}, {EMP_ID, EMP_NAME}, {EMP_ID, EMP_NAME, EMP_ZIP}, usw.Der Kandidatenschlüssel:
{EMP_ID}Die nicht-primären Attribute:
Alle Attribute außer EMP_ID sind keine primären AttributeDas Problem:
Hier haben wir das Problem, dass EMP_STATE und EMP_CITY abhängig von EMP_ZIP sind, was wiederum in Abhängigkeit zu EMP_ID steht. Die nicht-primären Attribute {EMP_STATE, EMP_CITY} besitzen also eine transitive Abhängigkeit für den Superschlüssel {EMP_ID}.
Um diese Abhängigkeit zu beseitigen, müssen wir mit den Spalten EMP_CITY und EMP_STATE eine neue Tabelle erzeugen, wobei EMP_ZIP als primärer Schlüssel dient:
Die Tabelle EMPLOYEE_DETAIL
| EMP_ID | EMP_NAME | EMP_ZIP |
|---|---|---|
| 222 | Harry | 201010 |
| 333 | Stephan | 02228 |
| 444 | Lan | 60007 |
| 555 | Katharine | 06389 |
| 666 | John | 462007 |
Die Tabelle EMPLOYEE_ZIP
| EMP_ZIP | EMP_STATE | EMP_CITY |
|---|---|---|
| 201010 | UP | Noida |
| 02228 | US | Boston |
| 60007 | US | Chicago |
| 06389 | UK | Norwich |
| 462007 | MP | Bhopal |
Zusammenfassung 3NF
Für gewöhnlich wird die 3NF in der ODS-Schicht eingesetzt. Es wird für das Beschaffen, Aufbereiten und Bereinigen von Informationen (meist für den Import in ein Data-Warehouse) verwendet.
Pros
- Modellierungstechniken sind einfach zu verstehen
- Kann zum Reduzieren von Duplikaten verwendet werden
- Kann zum Erreichen von Daten-Integrität verwendet werden
Cons
- Schlechte Leistung bei mehreren JOIN-Operationen
- Schwer zu laden (ETL)
- Änderungen können nur schwer gehandhabt werden
4NF – Die vierte Normalform
Eine Relation ist in 4NF (vierte Normalform), wenn sie in “Boyce Codd Normalform” (BCNF) ist und keine mehrwertigen Abhängigkeiten besitzt. Wenn für eine Abhängigkeit “A → B” für einen einzigen Wert A mehrere Werte für B existieren, liegt eine mehrwertige Abhängigkeit vor.
Betrachten wir folgendes Beispiel:
Die Tabelle STUDENT
| STU_ID | COURSE | HOBBY |
|---|---|---|
| 21 | Computer | Dancing |
| 21 | Math | Singing |
| 34 | Chemistry | Dancing |
| 74 | Biology | Cricket |
| 59 | Physics | Hockey |
Die gegebene Tabelle STUDENT ist in 3NF, aber bei den Spalten COURSE und HOBBY handelt es sich um zwei unabhängige Entitäten. Es besteht also keine Beziehung zwischen COURSE und HOBBY.
Innerhalb der Tabelle STUDENT finden wir eine STUD_ID 21, für die zwei Kurse (Computer und Math) und zwei Hobbies (Dancing und Singing). Wir haben also eine mehrwertige Abhängigkeit vorliegen, die für Redundanz in den Daten sorgt.
Um die Relation in 4NF zu bekommen, können wir die Tabelle STUDENT wie folgt aufspalten:
Die Tabelle STUDENT_COURSE
| STUD_ID | COURSE |
|---|---|
| 21 | Computer |
| 21 | Math |
| 34 | Chemistry |
| 74 | Biology |
| 59 | Physics |
Die Tabelle STUDENT_HOBBY
| STUD_ID | HOBBY |
|---|---|
| 21 | Dancing |
| 21 | Singing |
| 34 | Dancing |
| 74 | Cricket |
| 59 | Hockey |
5NF – Die fünfte Normalform
Eine Relation ist in 5NF (fünfte Normalform), wenn 4NF ist und keine JOIN-Abhängigkeiten besitzt und eine JOIN-Operation verlustfrei ist.
- 5NF liegt vor, wenn eine Relation in die größtmögliche Anzahl an Tabellen aufgespalten wird.
- 5NF wird oft auch als “Project-Join normal form” (PJ/NF) bezeichnet.
Betrachten wir das folgende Beispiel:
Die Tabelle STUDENT
| SUBJECT | LECUTRER | SEMESTER |
|---|---|---|
| Computer | Annika | Semester 1 |
| Computer | Denise | Semester 1 |
| Math | Denise | Semester 1 |
| Math | Simon | Semester 2 |
| Chemistry | Jannis | Semester 1 |
Der Tabelle können wir entnehmen, dass Denise die Kurse Computer und Mathematik in Semester 1 belegt, statt Mathematik in Semester 2 zu belegen. In diesem Fall werden alle Felder benötigt um valide Daten zu identifizieren.
Stellen wir uns nun einmal vor, wir fügen ein weiteres Semester, Semester 3, in die Tabelle ein, wissen aber noch nicht wer welche Kurse belegt. Wir müssten also LECTURER und SEMESTER als NULL deklarieren. Da die drei Spalten gemeinsam als Schlüssel fungieren, müssen aber ALLE Werte gesetzt sein.
Um also unsere gegebene Relation in die 5NF zu überführen, können wir die Tabelle STUDENT in drei Relationen STUDENT_SEM_SUB, STUDENT_SUB_LEC und STUDENT_SEM_LEC aufspalten.
Die Tabelle STUDENT_SEM_SUB
| SEMESTER | SUBJECT |
|---|---|
| Semester 1 | Computer |
| Semester 1 | Math |
| Semester 1 | Chemistry |
| Semester 2 | Math |
Die Tabelle STUDENT_SUB_LEC
| SEMESTER | LECTURER |
|---|---|
| Semester 1 | Annika |
| Semester 1 | Denise |
| Semester 1 | Denise |
| Semester 2 | Simon |
| Semester 1 | Jannis |
Vergleich 4NF und 5NF
| 4NF | 5NF |
|---|---|
| Eine Relation in 4NF ist auch in BCNF (Boyce Codd Normal Form). | Eine Relation in 5NF muss auch in 4NF sein. |
| Eine Relation in 4NF darf keine mehrwertigen Abhängigkeiten besitzen. | Eine Relation in 5NF darf keine JOIN-Abhängigkeiten besitzen. |
| Eine Relation in 4NF kann auch in 5NF sein. | Eine Relation in 5NF ist immer auch in 4NF. |
| Die 4NF ist nicht so mächtig wie 5NF im Bezug auf Vergleiche. | Die 5NF ist mächtiger als 4NF. |
| Eine Relation in 4NF enthält mehr Redundanz. | Eine Relation in 5NF enthält weniger Redundanz. |
| Eine Relation in 4NF kann in Unter-Relationen aufgespalten werden. | Eine Relation in 5NF kann nicht weiter aufgespalten werden ohne die Bedeutung oder Fakten zu verändern. |
Star-Schema
Eine besondere Form des multidimensionalen Datenmodells ist das Stern- bzw. Star-Schema. Dieses Schema wird vor allem im Bereich des Data-Warehousings und OLAP-Anwendungen eingesetzt und hat sich im Bezug auf die Abbildung multidimensionaler Datenstrukturen in relationalen Datenbanksystemen zum Standard entwickelt.
Ziel des Schemas ist es, beim Modellieren von relationalen Datenbanken die (meist) sehr hohe Anzahl an Tabellen zu minimieren. Der Name des Schemas rührt daher, dass die sog. Dimensionstabellen rings um eine Faktentabelle angeordnet und von dieser referenziert werden.
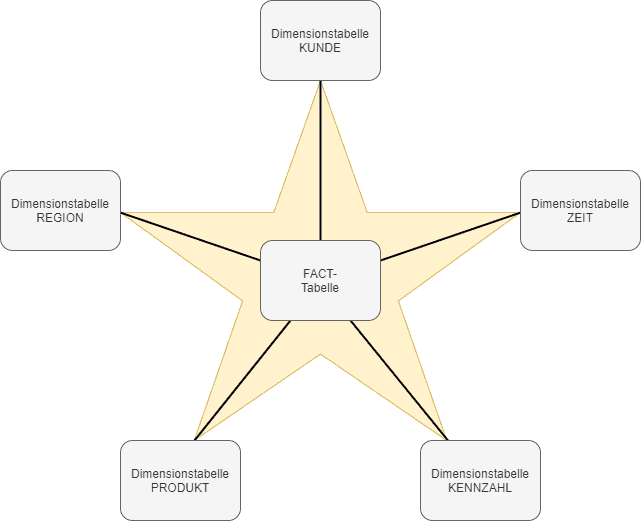
Die Dimensionstabellen stellen die qualitativen Daten zur Visualisierung der einzelnen Dimensionen und Dimensionshierarchien dar. Die Faktentabellen dienen zur Speicherung der abgeleiteten Werte und Größen wie beispielsweise Umsätze, Kosten, etc.
Aus Sicht eines Data-Cubes können die Dimensionen als die Dimensionsachsen verstanden werden. Die Faktentabelle würde dann den Würfelkern mit den tatsächlichen, faktischen Werten beschreiben.
Für Dimensionstabellen gilt, dass die Zeilen durch eine minimale Attributkombination identifiziert werden. Bei dieser Attributkombination handelt es sich um den Primärschlüssel. Um die Beziehung zwischen den Dimensionstabellen und den dazugehörigen Fakten modellieren zu können, werden die Primärschlüssel der Dimensionstabellen als Fremdschlüssel in die Faktentabelle aufgenommen. Innerhalb der Faktentabelle bilden diese dann wiederum zusammen den Primärschlüssel der Faktentabelle.
Betrachten dazu wir das folgende Beispiel:
-- =====================================================================
-- Datenbank
-- =====================================================================
CREATE DATABASE [DWH_Star]
GO
-- =====================================================================
-- Dimensionstabellen
-- =====================================================================
USE [DWH_Star]
GO
CREATE SCHEMA [dim];
GO
CREATE TABLE [dim].[server_names] (
[id] INT IDENTITY(1,1) PRIMARY KEY,
[server_name] NVARCHAR(1000) NOT NULL
);
GO
CREATE TABLE [dim].[server_ips] (
[id] INT IDENTITY(1,1) PRIMARY KEY,
[id_server_name] INT NOT NULL,
[server_ip] NVARCHAR(1000) NOT NULL
CONSTRAINT FK_server_name_ips FOREIGN KEY(id_server_name) REFERENCES [dim].[server_names](id)
);
GO
CREATE TABLE [dim].[server_locations] (
[id] INT IDENTITY(1,1) PRIMARY KEY,
[server_location] NVARCHAR(1000) NOT NULL
);
GO
CREATE TABLE [dim].[server_types] (
[id] INT IDENTITY(1,1) PRIMARY KEY,
[type] NVARCHAR(1000) NOT NULL
);
GO
-- =====================================================================
-- Faktentabelle
-- =====================================================================
CREATE SCHEMA fact;
GO
CREATE TABLE [fact].[table “” not found /]
(
[id] INT IDENTITY(1,1) PRIMARY KEY,
[id_server_name] INT NOT NULL,
[id_server_ip] INT NOT NULL,
[id_server_location] INT NOT NULL,
[id_server_type] INT NOT NULL,
[status] NVARCHAR(1000) NOT NULL
CONSTRAINT FK_server_names_fact FOREIGN KEY(id_server_name) REFERENCES [dim].[server_names] (id),
CONSTRAINT FK_server_ips_fact FOREIGN KEY(id_server_ip) REFERENCES [dim].[server_ips] (id),
CONSTRAINT FK_server_locations_fact FOREIGN KEY(id_server_location) REFERENCES [dim].[server_locations](id),
CONSTRAINT FK_server_types_fact FOREIGN KEY(id_server_type) REFERENCES [dim].[server_types] (id));
GOMit Hilfe des obigen Skripts wird eine neue Datenbank mit Namen DWH_Star, zwei Schemata dim und fact, vier simple Dimensionstabellen und eine Faktentabelle erzeugt.
In einem Verarbeitungsschritt können nun Informationen in unser DWH eingepflegt werden. Wir vereinfachen diesen Prozess in dem wir uns die folgenden Insert-Statements zur Hilfe nehmen:
id_server_name | id_server_ip | id_server_location | id_server_type | status
-------------------------------------------------------------------------------------------------
1 | 1 | 1 | 1 | Online
2 | 2 | 2 | 2 | OfflineDie Indizes beschreiben unsere Dimensionen, also Server-Name, Server-IP, Server-Location und Server-Type. Die Spalte Status beschreibt den Fakt, den wir mit unserer Tabelle modellieren wollen.
Mit Hilfe von JOIN-Operatoren kann die Faktentabelle aufgelöst werden, indem die Indexe dazu verwendet werden die Tatsächlichen Werte der Dimension zu bestimmen:
SELECT
sn.[server_name],
si.[server_ip],
sl.[server_location],
st.[type],
ft.[status]
FROM [fact].[table “” not found /]
ft
INNER JOIN [dim].[server_names] sn
ON ft.[id_server_name] = sn.[id]
INNER JOIN [dim].[server_ips] si
ON ft.[id_server_ip] = si.[id]
AND ft.[id_server_name] = si.[id_server_name]
INNER JOIN [dim].[server_locations] sl
ON ft.[id_server_location] = sl.[id]
INNER JOIN [dim].[server_types] st
ON ft.[id_server_type] = st.[id]Ziel des Star-Schemas ist nicht die Normalisierung der Daten, sondern die Optimierung für effiziente Leseoperationen. Dies liegt vor allem daran, dass die Informationen in den Dimensionstabellen oft in denormalisierter Form vorliegen. Es handelt sich dabei also um einen Kompromiss zwischen Redundanz und Verarbeitungsgeschwindigkeit zu Lasten des Speicherbedarfs.
Pros
- Einfaches Design
- Schnelle Abfragen
- Passt sehr gut zu OLAP Modellen
- Viele DBMS sind für Abfragen in Sternschemata optimiert
Cons
- Normalerweise Zentralisiert auf eine Faktentabelle
- Höhere Speichernutzung durch Denormalisierung innerhalb der Dimensionen
Unsere Expert:innen stehen Ihnen bei allen Fragen rund um Ihre IT Infrastruktur zur Seite.
Kontaktieren Sie uns gerne über das
Kontaktformular und vereinbaren ein unverbindliches
Beratungsgespräch mit unseren Berater:innen zur
Bedarfsevaluierung. Gemeinsam optimieren wir Ihre
Umgebung und steigern Ihre Performance!
Wir freuen uns auf Ihre Kontaktaufnahme!
55118 Mainz
info@madafa.de
+49 6131 3331612
Freitags:

